CuratedAtlasQuery is a query interface that allow the programmatic exploration and retrieval of the harmonised, curated and reannotated CELLxGENE single-cell human cell atlas. Data can be retrieved at cell, sample, or dataset levels based on filtering criteria.
Harmonised data is stored in the ARDC Nectar Research Cloud, and most CuratedAtlasQuery functions interact with Nectar via web requests, so a network connection is required for most functionality.
![]()
![]()
![]()
![]()
![]()
![]()
Query interface
Installation
devtools::install_github("stemangiola/CuratedAtlasQueryR")Load and explore the metadata
Load the metadata
# Note: in real applications you should use the default value of remote_url
metadata <- get_metadata(remote_url = METADATA_URL)
metadata
#> # Source: table</vast/scratch/users/milton.m/cache/R/CuratedAtlasQueryR/metadata.0.2.3.parquet> [?? x 56]
#> # Database: DuckDB 0.7.1 [unknown@Linux 3.10.0-1160.88.1.el7.x86_64:R 4.2.1/:memory:]
#> cell_ sample_ cell_…¹ cell_…² confi…³ cell_…⁴ cell_…⁵ cell_…⁶ sampl…⁷ _samp…⁸
#> <chr> <chr> <chr> <chr> <dbl> <chr> <chr> <chr> <chr> <chr>
#> 1 8387… 7bd7b8… natura… immune… 5 cd8 tem gmp natura… 842ce7… Q59___…
#> 2 1768… 7bd7b8… natura… immune… 5 cd8 tem cd8 tcm natura… 842ce7… Q59___…
#> 3 6329… 7bd7b8… natura… immune… 5 cd8 tem clp termin… 842ce7… Q59___…
#> 4 5027… 7bd7b8… natura… immune… 5 cd8 tem clp natura… 842ce7… Q59___…
#> 5 7956… 7bd7b8… natura… immune… 5 cd8 tem clp natura… 842ce7… Q59___…
#> 6 4305… 7bd7b8… natura… immune… 5 cd8 tem clp termin… 842ce7… Q59___…
#> 7 2126… 933f96… natura… ilc 1 nk nk natura… c250bf… AML3__…
#> 8 3114… 933f96… natura… immune… 5 mait nk natura… c250bf… AML3__…
#> 9 1407… 933f96… natura… immune… 5 mait clp natura… c250bf… AML3__…
#> 10 2911… 933f96… natura… nk 5 nk clp natura… c250bf… AML3__…
#> # … with more rows, 46 more variables: assay <chr>,
#> # assay_ontology_term_id <chr>, file_id_db <chr>,
#> # cell_type_ontology_term_id <chr>, development_stage <chr>,
#> # development_stage_ontology_term_id <chr>, disease <chr>,
#> # disease_ontology_term_id <chr>, ethnicity <chr>,
#> # ethnicity_ontology_term_id <chr>, experiment___ <chr>, file_id <chr>,
#> # is_primary_data_x <chr>, organism <chr>, organism_ontology_term_id <chr>, …The metadata variable can then be re-used for all subsequent queries.
Explore the tissue
metadata |>
dplyr::distinct(tissue, file_id)
#> # Source: SQL [10 x 2]
#> # Database: DuckDB 0.7.1 [unknown@Linux 3.10.0-1160.88.1.el7.x86_64:R 4.2.1/:memory:]
#> tissue file_id
#> <chr> <chr>
#> 1 bone marrow 1ff5cbda-4d41-4f50-8c7e-cbe4a90e38db
#> 2 lung parenchyma 6661ab3a-792a-4682-b58c-4afb98b2c016
#> 3 respiratory airway 6661ab3a-792a-4682-b58c-4afb98b2c016
#> 4 nose 6661ab3a-792a-4682-b58c-4afb98b2c016
#> 5 renal pelvis dc9d8cdd-29ee-4c44-830c-6559cb3d0af6
#> 6 kidney dc9d8cdd-29ee-4c44-830c-6559cb3d0af6
#> 7 renal medulla dc9d8cdd-29ee-4c44-830c-6559cb3d0af6
#> 8 cortex of kidney dc9d8cdd-29ee-4c44-830c-6559cb3d0af6
#> 9 kidney blood vessel dc9d8cdd-29ee-4c44-830c-6559cb3d0af6
#> 10 lung a2796032-d015-40c4-b9db-835207e5bd5bDownload single-cell RNA sequencing counts
Query raw counts
single_cell_counts =
metadata |>
dplyr::filter(
ethnicity == "African" &
stringr::str_like(assay, "%10x%") &
tissue == "lung parenchyma" &
stringr::str_like(cell_type, "%CD4%")
) |>
get_single_cell_experiment()
#> ℹ Realising metadata.
#> ℹ Synchronising files
#> ℹ Downloading 0 files, totalling 0 GB
#> ℹ Reading files.
#> ℹ Compiling Single Cell Experiment.
single_cell_counts
#> # A SingleCellExperiment-tibble abstraction: 1,571 × 57
#> # [90mFeatures=36229 | Cells=1571 | Assays=counts[0m
#> .cell sample_ cell_…¹ cell_…² confi…³ cell_…⁴ cell_…⁵ cell_…⁶ sampl…⁷ X_sam…⁸
#> <chr> <chr> <chr> <chr> <dbl> <chr> <chr> <chr> <chr> <chr>
#> 1 AGCG… 11a7dc… CD4-po… cd4 th1 3 cd4 tcm cd8 t th1 10b339… Donor_…
#> 2 TCAG… 11a7dc… CD4-po… cd4 th… 3 cd4 tcm cd4 tem th1/th… 10b339… Donor_…
#> 3 TTTA… 11a7dc… CD4-po… cd4 th… 3 cd4 tcm cd4 tcm th17 10b339… Donor_…
#> 4 ACAC… 11a7dc… CD4-po… immune… 5 cd4 tcm plasma th1/th… 10b339… Donor_…
#> 5 CAAG… 11a7dc… CD4-po… immune… 1 cd4 tcm cd4 tcm mait 10b339… Donor_…
#> 6 CTGT… 14a078… CD4-po… cd4 th… 3 cd4 tcm cd4 tem th1/th… 8f71c5… VUHD85…
#> 7 ACGT… 14a078… CD4-po… treg 5 cd4 tcm tregs t regu… 8f71c5… VUHD85…
#> 8 CATA… 14a078… CD4-po… immune… 5 nk cd8 tem mait 8f71c5… VUHD85…
#> 9 ACTT… 14a078… CD4-po… mait 5 mait cd8 tem mait 8f71c5… VUHD85…
#> 10 TGCG… 14a078… CD4-po… cd4 th1 3 cd4 tcm cd4 tem th1 8f71c5… VUHD85…
#> # … with 1,561 more rows, 47 more variables: assay <chr>,
#> # assay_ontology_term_id <chr>, file_id_db <chr>,
#> # cell_type_ontology_term_id <chr>, development_stage <chr>,
#> # development_stage_ontology_term_id <chr>, disease <chr>,
#> # disease_ontology_term_id <chr>, ethnicity <chr>,
#> # ethnicity_ontology_term_id <chr>, experiment___ <chr>, file_id <chr>,
#> # is_primary_data_x <chr>, organism <chr>, organism_ontology_term_id <chr>, …Query counts scaled per million
This is helpful if just few genes are of interest, as they can be compared across samples.
single_cell_counts =
metadata |>
dplyr::filter(
ethnicity == "African" &
stringr::str_like(assay, "%10x%") &
tissue == "lung parenchyma" &
stringr::str_like(cell_type, "%CD4%")
) |>
get_single_cell_experiment(assays = "cpm")
#> ℹ Realising metadata.
#> ℹ Synchronising files
#> ℹ Downloading 0 files, totalling 0 GB
#> ℹ Reading files.
#> ℹ Compiling Single Cell Experiment.
single_cell_counts
#> # A SingleCellExperiment-tibble abstraction: 1,571 × 57
#> # [90mFeatures=36229 | Cells=1571 | Assays=cpm[0m
#> .cell sample_ cell_…¹ cell_…² confi…³ cell_…⁴ cell_…⁵ cell_…⁶ sampl…⁷ X_sam…⁸
#> <chr> <chr> <chr> <chr> <dbl> <chr> <chr> <chr> <chr> <chr>
#> 1 AGCG… 11a7dc… CD4-po… cd4 th1 3 cd4 tcm cd8 t th1 10b339… Donor_…
#> 2 TCAG… 11a7dc… CD4-po… cd4 th… 3 cd4 tcm cd4 tem th1/th… 10b339… Donor_…
#> 3 TTTA… 11a7dc… CD4-po… cd4 th… 3 cd4 tcm cd4 tcm th17 10b339… Donor_…
#> 4 ACAC… 11a7dc… CD4-po… immune… 5 cd4 tcm plasma th1/th… 10b339… Donor_…
#> 5 CAAG… 11a7dc… CD4-po… immune… 1 cd4 tcm cd4 tcm mait 10b339… Donor_…
#> 6 CTGT… 14a078… CD4-po… cd4 th… 3 cd4 tcm cd4 tem th1/th… 8f71c5… VUHD85…
#> 7 ACGT… 14a078… CD4-po… treg 5 cd4 tcm tregs t regu… 8f71c5… VUHD85…
#> 8 CATA… 14a078… CD4-po… immune… 5 nk cd8 tem mait 8f71c5… VUHD85…
#> 9 ACTT… 14a078… CD4-po… mait 5 mait cd8 tem mait 8f71c5… VUHD85…
#> 10 TGCG… 14a078… CD4-po… cd4 th1 3 cd4 tcm cd4 tem th1 8f71c5… VUHD85…
#> # … with 1,561 more rows, 47 more variables: assay <chr>,
#> # assay_ontology_term_id <chr>, file_id_db <chr>,
#> # cell_type_ontology_term_id <chr>, development_stage <chr>,
#> # development_stage_ontology_term_id <chr>, disease <chr>,
#> # disease_ontology_term_id <chr>, ethnicity <chr>,
#> # ethnicity_ontology_term_id <chr>, experiment___ <chr>, file_id <chr>,
#> # is_primary_data_x <chr>, organism <chr>, organism_ontology_term_id <chr>, …Extract only a subset of genes
single_cell_counts =
metadata |>
dplyr::filter(
ethnicity == "African" &
stringr::str_like(assay, "%10x%") &
tissue == "lung parenchyma" &
stringr::str_like(cell_type, "%CD4%")
) |>
get_single_cell_experiment(assays = "cpm", features = "PUM1")
#> ℹ Realising metadata.
#> ℹ Synchronising files
#> ℹ Downloading 0 files, totalling 0 GB
#> ℹ Reading files.
#> ℹ Compiling Single Cell Experiment.
single_cell_counts
#> # A SingleCellExperiment-tibble abstraction: 1,571 × 57
#> # [90mFeatures=1 | Cells=1571 | Assays=cpm[0m
#> .cell sample_ cell_…¹ cell_…² confi…³ cell_…⁴ cell_…⁵ cell_…⁶ sampl…⁷ X_sam…⁸
#> <chr> <chr> <chr> <chr> <dbl> <chr> <chr> <chr> <chr> <chr>
#> 1 AGCG… 11a7dc… CD4-po… cd4 th1 3 cd4 tcm cd8 t th1 10b339… Donor_…
#> 2 TCAG… 11a7dc… CD4-po… cd4 th… 3 cd4 tcm cd4 tem th1/th… 10b339… Donor_…
#> 3 TTTA… 11a7dc… CD4-po… cd4 th… 3 cd4 tcm cd4 tcm th17 10b339… Donor_…
#> 4 ACAC… 11a7dc… CD4-po… immune… 5 cd4 tcm plasma th1/th… 10b339… Donor_…
#> 5 CAAG… 11a7dc… CD4-po… immune… 1 cd4 tcm cd4 tcm mait 10b339… Donor_…
#> 6 CTGT… 14a078… CD4-po… cd4 th… 3 cd4 tcm cd4 tem th1/th… 8f71c5… VUHD85…
#> 7 ACGT… 14a078… CD4-po… treg 5 cd4 tcm tregs t regu… 8f71c5… VUHD85…
#> 8 CATA… 14a078… CD4-po… immune… 5 nk cd8 tem mait 8f71c5… VUHD85…
#> 9 ACTT… 14a078… CD4-po… mait 5 mait cd8 tem mait 8f71c5… VUHD85…
#> 10 TGCG… 14a078… CD4-po… cd4 th1 3 cd4 tcm cd4 tem th1 8f71c5… VUHD85…
#> # … with 1,561 more rows, 47 more variables: assay <chr>,
#> # assay_ontology_term_id <chr>, file_id_db <chr>,
#> # cell_type_ontology_term_id <chr>, development_stage <chr>,
#> # development_stage_ontology_term_id <chr>, disease <chr>,
#> # disease_ontology_term_id <chr>, ethnicity <chr>,
#> # ethnicity_ontology_term_id <chr>, experiment___ <chr>, file_id <chr>,
#> # is_primary_data_x <chr>, organism <chr>, organism_ontology_term_id <chr>, …Extract the counts as a Seurat object
This convert the H5 SingleCellExperiment to Seurat so it might take long time and occupy a lot of memory depending on how many cells you are requesting.
single_cell_counts_seurat =
metadata |>
dplyr::filter(
ethnicity == "African" &
stringr::str_like(assay, "%10x%") &
tissue == "lung parenchyma" &
stringr::str_like(cell_type, "%CD4%")
) |>
get_seurat()
#> ℹ Realising metadata.
#> ℹ Synchronising files
#> ℹ Downloading 0 files, totalling 0 GB
#> ℹ Reading files.
#> ℹ Compiling Single Cell Experiment.
single_cell_counts_seurat
#> An object of class Seurat
#> 36229 features across 1571 samples within 1 assay
#> Active assay: originalexp (36229 features, 0 variable features)Save your SingleCellExperiment
The returned SingleCellExperiment can be saved with two modalities, as .rds or as HDF5.
Saving as RDS (fast saving, slow reading)
Saving as .rds has the advantage of being fast, andd the .rds file occupies very little disk space as it only stores the links to the files in your cache.
However it has the disadvantage that for big SingleCellExperiment objects, which merge a lot of HDF5 from your get_single_cell_experiment, the display and manipulation is going to be slow. In addition, an .rds saved in this way is not portable: you will not be able to share it with other users.
single_cell_counts |> saveRDS("single_cell_counts.rds")Saving as HDF5 (slow saving, fast reading)
Saving as .hdf5 executes any computation on the SingleCellExperiment and writes it to disk as a monolithic HDF5. Once this is done, operations on the SingleCellExperiment will be comparatively very fast. The resulting .hdf5 file will also be totally portable and sharable.
However this .hdf5 has the disadvantage of being larger than the corresponding .rds as it includes a copy of the count information, and the saving process is going to be slow for large objects.
single_cell_counts |> HDF5Array::saveHDF5SummarizedExperiment("single_cell_counts", replace = TRUE)Visualise gene transcription
We can gather all CD14 monocytes cells and plot the distribution of HLA-A across all tissues
#> ℹ Realising metadata.
#> ℹ Synchronising files
#> ℹ Downloading 0 files, totalling 0 GB
#> ℹ Reading files.
#> ℹ Compiling Single Cell Experiment.
#> Warning: Transformation introduced infinite values in continuous y-axis
#> Warning in min(x): no non-missing arguments to min; returning Inf
#> Warning in max(x): no non-missing arguments to max; returning -Inf
#> Warning: Transformation introduced infinite values in continuous y-axis
#> Warning in min(x): no non-missing arguments to min; returning Inf
#> Warning in max(x): no non-missing arguments to max; returning -Inf
library(tidySingleCellExperiment)
library(ggplot2)
counts |>
ggplot(aes( disease, `HLA.A`,color = file_id)) +
geom_jitter(shape=".") 
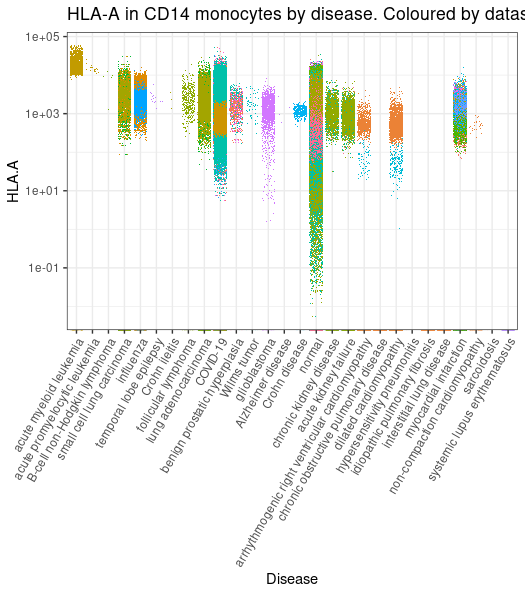
metadata |>
# Filter and subset
dplyr::filter(cell_type_harmonised=="nk") |>
# Get counts per million for HCA-A gene
get_single_cell_experiment(assays = "cpm", features = "HLA-A") |>
# Plot (styling code have been omitted)
tidySingleCellExperiment::join_features("HLA-A", shape = "wide") |>
ggplot(aes(tissue_harmonised, `HLA.A`,color = file_id)) +
geom_jitter(shape=".")
#> ℹ Realising metadata.
#> ℹ Synchronising files
#> ℹ Downloading 0 files, totalling 0 GB
#> ℹ Reading files.
#> ℹ Compiling Single Cell Experiment.
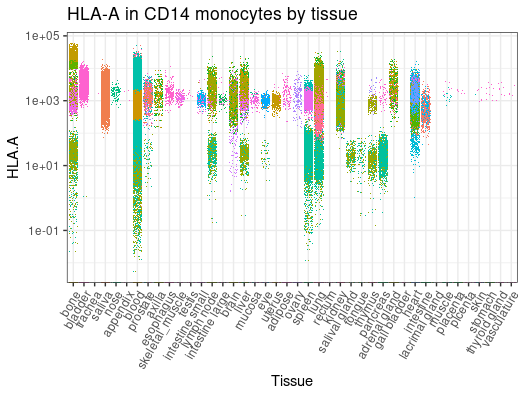
Obtain Unharmonised Metadata
Various metadata fields are not common between datasets, so it does not make sense for these to live in the main metadata table. However, we can obtain it using the get_unharmonised_metadata() function. This function returns a data frame with one row per dataset, including the unharmonised column which contains unharmnised metadata as a nested data frame.
harmonised <- metadata |> dplyr::filter(tissue == "kidney blood vessel")
unharmonised <- get_unharmonised_metadata(harmonised)
unharmonised
#> # A tibble: 1 × 2
#> file_id unharmonised
#> <chr> <list>
#> 1 dc9d8cdd-29ee-4c44-830c-6559cb3d0af6 <tbl_dck_[,14]>Notice that the columns differ between each dataset’s data frame:
dplyr::pull(unharmonised) |> head(2)
#> [[1]]
#> # Source: SQL [?? x 14]
#> # Database: DuckDB 0.7.1 [unknown@Linux 3.10.0-1160.88.1.el7.x86_64:R 4.2.1/:memory:]
#> cell_ file_id donor…¹ donor…² libra…³ mappe…⁴ sampl…⁵ suspe…⁶ suspe…⁷ autho…⁸
#> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 4602… dc9d8c… 27 mon… a8536b… 5ddaea… GENCOD… 61bf84… cell d8a44f… Pelvic…
#> 2 4602… dc9d8c… 27 mon… a8536b… 5ddaea… GENCOD… 61bf84… cell d8a44f… Pelvic…
#> 3 4602… dc9d8c… 27 mon… a8536b… 5ddaea… GENCOD… 61bf84… cell d8a44f… Pelvic…
#> 4 4602… dc9d8c… 27 mon… a8536b… 5ddaea… GENCOD… 61bf84… cell d8a44f… Pelvic…
#> 5 4602… dc9d8c… 27 mon… a8536b… 5ddaea… GENCOD… 61bf84… cell d8a44f… Pelvic…
#> 6 4602… dc9d8c… 27 mon… a8536b… 5ddaea… GENCOD… 61bf84… cell d8a44f… Pelvic…
#> 7 4602… dc9d8c… 27 mon… a8536b… 5ddaea… GENCOD… 61bf84… cell d8a44f… Pelvic…
#> 8 4602… dc9d8c… 27 mon… a8536b… 5ddaea… GENCOD… 61bf84… cell d8a44f… Pelvic…
#> 9 4602… dc9d8c… 27 mon… a8536b… 5ddaea… GENCOD… 61bf84… cell d8a44f… Pelvic…
#> 10 4602… dc9d8c… 27 mon… a8536b… 5ddaea… GENCOD… 61bf84… cell d8a44f… Pelvic…
#> # … with more rows, 4 more variables: reported_diseases <chr>,
#> # Experiment <chr>, Project <chr>, broad_celltype <chr>, and abbreviated
#> # variable names ¹donor_age, ²donor_uuid, ³library_uuid,
#> # ⁴mapped_reference_annotation, ⁵sample_uuid, ⁶suspension_type,
#> # ⁷suspension_uuid, ⁸author_cell_typeCell metadata
Dataset-specific columns (definitions available at cellxgene.cziscience.com)
cell_count, collection_id, created_at.x, created_at.y, dataset_deployments, dataset_id, file_id, filename, filetype, is_primary_data.y, is_valid, linked_genesets, mean_genes_per_cell, name, published, published_at, revised_at, revision, s3_uri, schema_version, tombstone, updated_at.x, updated_at.y, user_submitted, x_normalization
Sample-specific columns (definitions available at cellxgene.cziscience.com)
sample_, sample_name, age_days, assay, assay_ontology_term_id, development_stage, development_stage_ontology_term_id, ethnicity, ethnicity_ontology_term_id, experiment___, organism, organism_ontology_term_id, sample_placeholder, sex, sex_ontology_term_id, tissue, tissue_harmonised, tissue_ontology_term_id, disease, disease_ontology_term_id, is_primary_data.x
Cell-specific columns (definitions available at cellxgene.cziscience.com)
cell_, cell_type, cell_type_ontology_term_idm, cell_type_harmonised, confidence_class, cell_annotation_azimuth_l2, cell_annotation_blueprint_singler
Through harmonisation and curation we introduced custom column, not present in the original CELLxGENE metadata
-
tissue_harmonised: a coarser tissue name for better filtering -
age_days: the number of days corresponding to the age -
cell_type_harmonised: the consensus call identity (for immune cells) using the original and three novel annotations using Seurat Azimuth and SingleR -
confidence_class: an ordinal class of how confidentcell_type_harmonisedis. 1 is complete consensus, 2 is 3 out of four and so on.
-
cell_annotation_azimuth_l2: Azimuth cell annotation -
cell_annotation_blueprint_singler: SingleR cell annotation using Blueprint reference -
cell_annotation_blueprint_monaco: SingleR cell annotation using Monaco reference -
sample_id_db: Sample subdivision for internal use -
file_id_db: File subdivision for internal use -
sample_: Sample ID -
.sample_name: How samples were defined
RNA abundance
The raw assay includes RNA abundance in the positive real scale (not transformed with non-linear functions, e.g. log sqrt). Originally CELLxGENE include a mix of scales and transformations specified in the x_normalization column.
The cpm assay includes counts per million.
Session Info
sessionInfo()
#> R version 4.2.1 (2022-06-23)
#> Platform: x86_64-pc-linux-gnu (64-bit)
#> Running under: CentOS Linux 7 (Core)
#>
#> Matrix products: default
#> BLAS: /stornext/System/data/apps/R/R-4.2.1/lib64/R/lib/libRblas.so
#> LAPACK: /stornext/System/data/apps/R/R-4.2.1/lib64/R/lib/libRlapack.so
#>
#> locale:
#> [1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
#> [3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
#> [5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
#> [7] LC_PAPER=en_US.UTF-8 LC_NAME=C
#> [9] LC_ADDRESS=C LC_TELEPHONE=C
#> [11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
#>
#> attached base packages:
#> [1] stats4 stats graphics grDevices utils datasets methods
#> [8] base
#>
#> other attached packages:
#> [1] tidySingleCellExperiment_1.6.3 SingleCellExperiment_1.18.1
#> [3] SummarizedExperiment_1.26.1 Biobase_2.56.0
#> [5] GenomicRanges_1.48.0 GenomeInfoDb_1.32.4
#> [7] IRanges_2.30.1 S4Vectors_0.34.0
#> [9] BiocGenerics_0.42.0 MatrixGenerics_1.8.1
#> [11] matrixStats_0.63.0 ttservice_0.2.2
#> [13] ggplot2_3.4.1 CuratedAtlasQueryR_0.99.1
#>
#> loaded via a namespace (and not attached):
#> [1] plyr_1.8.8 igraph_1.4.1 lazyeval_0.2.2
#> [4] sp_1.5-1 splines_4.2.1 listenv_0.9.0
#> [7] scattermore_0.8 digest_0.6.31 htmltools_0.5.4
#> [10] fansi_1.0.3 magrittr_2.0.3 tensor_1.5
#> [13] cluster_2.1.3 ROCR_1.0-11 globals_0.16.2
#> [16] duckdb_0.7.1-1 spatstat.sparse_3.0-0 colorspace_2.0-3
#> [19] blob_1.2.3 ggrepel_0.9.2 xfun_0.36
#> [22] dplyr_1.1.0 RCurl_1.98-1.9 jsonlite_1.8.4
#> [25] progressr_0.13.0 spatstat.data_3.0-0 survival_3.3-1
#> [28] zoo_1.8-11 glue_1.6.2 polyclip_1.10-4
#> [31] gtable_0.3.1 zlibbioc_1.42.0 XVector_0.36.0
#> [34] leiden_0.4.3 DelayedArray_0.22.0 Rhdf5lib_1.18.2
#> [37] future.apply_1.10.0 HDF5Array_1.24.2 abind_1.4-5
#> [40] scales_1.2.1 DBI_1.1.3 spatstat.random_3.0-1
#> [43] miniUI_0.1.1.1 Rcpp_1.0.10 viridisLite_0.4.1
#> [46] xtable_1.8-4 reticulate_1.26 htmlwidgets_1.6.0
#> [49] httr_1.4.4 RColorBrewer_1.1-3 ellipsis_0.3.2
#> [52] Seurat_4.3.0 ica_1.0-3 farver_2.1.1
#> [55] pkgconfig_2.0.3 dbplyr_2.3.0 sass_0.4.4
#> [58] uwot_0.1.14 deldir_1.0-6 utf8_1.2.2
#> [61] labeling_0.4.2 tidyselect_1.2.0 rlang_1.0.6
#> [64] reshape2_1.4.4 later_1.3.0 munsell_0.5.0
#> [67] tools_4.2.1 cachem_1.0.6 cli_3.6.0
#> [70] generics_0.1.3 ggridges_0.5.4 evaluate_0.19
#> [73] stringr_1.5.0 fastmap_1.1.0 yaml_2.3.6
#> [76] goftest_1.2-3 knitr_1.42 fitdistrplus_1.1-8
#> [79] purrr_1.0.1 RANN_2.6.1 pbapply_1.6-0
#> [82] future_1.30.0 nlme_3.1-157 mime_0.12
#> [85] compiler_4.2.1 rstudioapi_0.14 curl_4.3.3
#> [88] plotly_4.10.1 png_0.1-8 spatstat.utils_3.0-1
#> [91] tibble_3.1.8 bslib_0.4.2 stringi_1.7.12
#> [94] highr_0.10 forcats_1.0.0 lattice_0.20-45
#> [97] Matrix_1.5-3 vctrs_0.5.2 pillar_1.8.1
#> [100] lifecycle_1.0.3 rhdf5filters_1.8.0 spatstat.geom_3.0-3
#> [103] lmtest_0.9-40 jquerylib_0.1.4 RcppAnnoy_0.0.20
#> [106] data.table_1.14.6 cowplot_1.1.1 bitops_1.0-7
#> [109] irlba_2.3.5.1 httpuv_1.6.7 patchwork_1.1.2
#> [112] R6_2.5.1 promises_1.2.0.1 KernSmooth_2.23-20
#> [115] gridExtra_2.3 parallelly_1.33.0 codetools_0.2-18
#> [118] assertthat_0.2.1 MASS_7.3-57 rhdf5_2.40.0
#> [121] rprojroot_2.0.3 withr_2.5.0 SeuratObject_4.1.3
#> [124] sctransform_0.3.5 GenomeInfoDbData_1.2.8 parallel_4.2.1
#> [127] grid_4.2.1 tidyr_1.3.0 rmarkdown_2.20
#> [130] Rtsne_0.16 spatstat.explore_3.0-5 shiny_1.7.4