使用limma、Glimma和edgeR,RNA-seq数据分析易如反掌
Xueyi Dong
The Walter and Eliza Hall Institute of Medical Research, 1G Royal Parade, Parkville, VIC 3052, Melbourne, AustraliaCharity Law
The Walter and Eliza Hall Institute of Medical Research, 1G Royal Parade, Parkville, VIC 3052, Melbourne, Australia; Department of Medical Biology, The University of Melbourne, Parkville, VIC 3010, Melbourne, AustraliaMonther Alhamdoosh
CSL Limited, Bio21 Institute, 30 Flemington Road, Parkville, Victoria 3010, AustraliaShian Su
The Walter and Eliza Hall Institute of Medical Research, 1G Royal Parade, Parkville, VIC 3052, Melbourne, AustraliaLuyi Tian
The Walter and Eliza Hall Institute of Medical Research, 1G Royal Parade, Parkville, VIC 3052, Melbourne, Australia; Department of Medical Biology, The University of Melbourne, Parkville, VIC 3010, Melbourne, AustraliaGordon K. Smyth
The Walter and Eliza Hall Institute of Medical Research, 1G Royal Parade, Parkville, VIC 3052, Melbourne, Australia; School of Mathematics and Statistics, The University of Melbourne, Parkville, VIC 3010, Melbourne, AustraliaMatthew E. Ritchie
The Walter and Eliza Hall Institute of Medical Research, 1G Royal Parade, Parkville, VIC 3052, Melbourne, Australia; Department of Medical Biology, The University of Melbourne, Parkville, VIC 3010, Melbourne, Australia; School of Mathematics and Statistics, The University of Melbourne, Parkville, VIC 3010, Melbourne, Australia2018年12月17日
Source:vignettes/limmaWorkflow_chinese.Rmd
limmaWorkflow_chinese.Rmd
摘要
简单且高效地分析RNA测序数据的能力正是Bioconductor的核心优势之一。在获得RNA-seq基因表达矩阵后,通常需要对数据进行预处理、探索性数据分析、差异表达检验以及通路分析,以得到可以帮助进一步实验和验证研究的结果。在本工作流程中,我们将通过分析来自小鼠乳腺的RNA测序数据,演示如何使用流行的edgeR包载入、整理、过滤和归一化数据,然后用limma包的voom方法、线性模型和经验贝叶斯调节来评估差异表达并进行基因集检验。通过Glimma包,本流程进一步实现了结果的互动探索,便于用户查看特定样本与基因的分析结果。通过使用这三个Bioconductor包,研究者可以轻松地运行完整的RNA-seq数据分析流程,从原始计数(raw counts)中挖掘出其中蕴含的生物学意义。
背景介绍
RNA测序(RNA-seq)是用于研究基因表达的重要技术。其中,在基因组规模下检测多条件之间基因的差异表达是研究者最常探究的问题之一。对于RNA-seq数据,来自Bioconductor项目(Huber et al. 2015)的 edgeR (Robinson, McCarthy, and Smyth 2010)和limma包 (Ritchie et al. 2015)提供了一套用于处理此问题的完善的统计学方法。
在这篇文章中,我们描述了一个用于分析RNA-seq数据的edgeR - limma工作流程,使用基因水平的计数(gene-level counts)作为输入,经过预处理和探索性数据分析,然后得到差异表达(DE)基因和基因表达特征(gene signatures)的列表。Glimma包(Su et al. 2017)提供的交互式图表可以同时呈现整体样本层面与单个基因层面的数据,相对静态的R图表而言,更便于我们探索更多的细节。
此工作流程中我们分析的数据来自Sheridan等人的实验(2015)(Sheridan et al. 2015),它包含三个细胞群,即基底(basal)、管腔祖细胞(liminal progenitor, LP)和成熟管腔(mature luminal, ML)。细胞群皆分选自雌性处女小鼠的乳腺,每种都设三个生物学重复。RNA样品分三个批次使用Illumina HiSeq 2000进行测序,得到长为100碱基对的单端序列片段。
本文所述的分析流程假设从RNA-seq实验获得的序列片段已经与适当的参考基因组比对,并已经在基因水平上对序列进行了统计计数。在本文条件下,使用Rsubread包提供的基于R的流程将序列片段与小鼠参考基因组(mm10)比对(具体而言,先使用align函数(Liao, Smyth, and Shi 2013)进行比对,然后使用featureCounts (Liao, Smyth, and Shi 2014)函数,利用其内置的基于RefSeq的mm10注释进行基因水平的总结)。
这些样本的计数数据可以从Gene Expression Omnibus (GEO)数据库 http://www.ncbi.nlm.nih.gov/geo/使用GEO序列登记号GSE63310下载。更多关于实验设计和样品制备的信息也可以在GEO使用该登记号查看。
数据整合
读入计数数据
首先,从压缩文件GSE63310_RAW.tar中解压出相关的文件。下方的代码将完成此步骤,或者您也可以手动进行这一步并继续后续分析。
utils::untar(system.file("extdata", "GSE63310_RAW.tar", package = "zhejiang2020"), exdir = ".")
files <- c("GSM1545535_10_6_5_11.txt", "GSM1545536_9_6_5_11.txt", "GSM1545538_purep53.txt",
"GSM1545539_JMS8-2.txt", "GSM1545540_JMS8-3.txt", "GSM1545541_JMS8-4.txt",
"GSM1545542_JMS8-5.txt", "GSM1545544_JMS9-P7c.txt", "GSM1545545_JMS9-P8c.txt")
for(i in paste(files, ".gz", sep=""))
R.utils::gunzip(i, overwrite=TRUE)每一个文本文件均为对应样品的原始基因水平计数矩阵。需要注意我们的这次分析仅包含了此实验中的basal、LP和ML样品(可见下方所示文件名)。
files <- c("GSM1545535_10_6_5_11.txt", "GSM1545536_9_6_5_11.txt",
"GSM1545538_purep53.txt", "GSM1545539_JMS8-2.txt",
"GSM1545540_JMS8-3.txt", "GSM1545541_JMS8-4.txt",
"GSM1545542_JMS8-5.txt", "GSM1545544_JMS9-P7c.txt",
"GSM1545545_JMS9-P8c.txt")
read.delim(files[1], nrow=5)## EntrezID GeneLength Count
## 1 497097 3634 1
## 2 100503874 3259 0
## 3 100038431 1634 0
## 4 19888 9747 0
## 5 20671 3130 1相比于分别读入这九个文本文件然后合并为一个计数矩阵,edgeR提供了更方便的途径,使用readDGE函数即可一步完成。得到的DGEList对象中包含一个计数矩阵,它的27179行分别对应每个基因不重复的Entrez基因ID,九列分别对应此实验中的每个样品。
## [1] "DGEList"
## attr(,"package")
## [1] "edgeR"
dim(x)## [1] 27179 9如果数据不是每个样品一个文件的形式,而是一个包含所有样品的计数的文件,则可以先将文件读入R,再使用DGEList函数转换为一个DGEList对象。
组织样品信息
为进行下游分析,需要将有关实验设计的样品信息与计数矩阵的列关联起来。这里需要包括各种对表达水平有影响的实验变量,无论是生物变量还是技术变量。例如,细胞类型(在这个实验中是basal、LP和ML)、基因型(野生型、敲除)、表型(疾病状态、性别、年龄)、样品处理(用药、对照)和批次信息(如果样品是在不同时间点进行收集和分析的,需要记录进行实验的时间)等。
我们的DGEList对象中包含的samples数据框同时存储了细胞类型(group)和批次(测序泳道lane)信息,每种信息都包含三个不同的水平。在x$samples中,程序会自动计算每个样品的文库大小(即样品的总序列计数),归一化系数会被预先设置为1。 为了方便阅读,我们从DGEList对象x的列名中删去了GEO样品ID(GSM*)。
## [1] "10_6_5_11" "9_6_5_11" "purep53" "JMS8-2" "JMS8-3" "JMS8-4" "JMS8-5"
## [8] "JMS9-P7c" "JMS9-P8c"
colnames(x) <- samplenames
group <- as.factor(c("LP", "ML", "Basal", "Basal", "ML", "LP",
"Basal", "ML", "LP"))
x$samples$group <- group
lane <- as.factor(rep(c("L004","L006","L008"), c(3,4,2)))
x$samples$lane <- lane
x$samples## files group lib.size norm.factors lane
## 10_6_5_11 GSM1545535_10_6_5_11.txt LP 32863052 1 L004
## 9_6_5_11 GSM1545536_9_6_5_11.txt ML 35335491 1 L004
## purep53 GSM1545538_purep53.txt Basal 57160817 1 L004
## JMS8-2 GSM1545539_JMS8-2.txt Basal 51368625 1 L006
## JMS8-3 GSM1545540_JMS8-3.txt ML 75795034 1 L006
## JMS8-4 GSM1545541_JMS8-4.txt LP 60517657 1 L006
## JMS8-5 GSM1545542_JMS8-5.txt Basal 55086324 1 L006
## JMS9-P7c GSM1545544_JMS9-P7c.txt ML 21311068 1 L008
## JMS9-P8c GSM1545545_JMS9-P8c.txt LP 19958838 1 L008组织基因注释
我们的DGEList对象中的第二个数据框名为genes,用于存储与计数矩阵的行相关联的基因信息。 为检索这些信息,我们可以使用特定物种的注释包,比如小鼠的Mus.musculus (Bioconductor Core Team 2016b)(或人类的Homo.sapiens (Bioconductor Core Team 2016a));或者也可以使用biomaRt 包 (Durinck et al. 2005, 2009),它通过接入Ensembl genome数据库来进行基因注释。
可以检索的信息类型包括基因符号(gene symbols)、基因名称(gene names)、染色体名称和位置、Entrez基因ID、Refseq基因ID和Ensembl基因ID等。biomaRt主要通过Ensembl基因ID进行检索,而Mus.musculus包含来自不同来源的信息,允许用户从不同基因ID中选择某一种作为检索键。
我们使用Mus.musculus包,利用我们数据集中的Entrez基因ID来检索相关的基因符号和染色体信息。
geneid <- rownames(x)
genes <- select(Mus.musculus, keys=geneid, columns=c("SYMBOL", "TXCHROM"),
keytype="ENTREZID")
head(genes)## ENTREZID SYMBOL TXCHROM
## 1 497097 Xkr4 chr1
## 2 100503874 Gm19938 <NA>
## 3 100038431 Gm10568 <NA>
## 4 19888 Rp1 chr1
## 5 20671 Sox17 chr1
## 6 27395 Mrpl15 chr1与任何基因ID一样,Entrez基因ID可能不能一对一地匹配我们想获得的基因信息。在处理之前,检查重复的基因ID和弄清楚重复的来源非常重要。我们的基因注释中包含28个能匹配到多个不同染色体的基因(比如基因Gm1987关联于染色体chr4和chr4_JH584294_random,小RNA Mir5098关联于chr2,chr5,chr8,chr11和chr17)。 为了处理重复的基因ID,我们可以合并来自多重匹配基因的所有染色体信息,比如将基因Gm1987分配到chr4 and chr4_JH584294_random,或选取其中一条染色体来代表具有重复注释的基因。为了简单起见,我们选择后者,保留每个基因ID第一次出现的信息。
genes <- genes[!duplicated(genes$ENTREZID),]在此例子中,注释与数据对象中的基因顺序是相同的。如果由于缺失和/或重新排列基因ID导致其顺序不一致,我们可以用match函数来正确排序基因。然后,我们将基因注释的数据框添加到DGEList对象,数据的整合就完成了,此时的数据对象中含有原始计数数据以及相关的样品信息和基因注释。
x$genes <- genes
x## An object of class "DGEList"
## $samples
## files group lib.size norm.factors lane
## 10_6_5_11 GSM1545535_10_6_5_11.txt LP 32863052 1 L004
## 9_6_5_11 GSM1545536_9_6_5_11.txt ML 35335491 1 L004
## purep53 GSM1545538_purep53.txt Basal 57160817 1 L004
## JMS8-2 GSM1545539_JMS8-2.txt Basal 51368625 1 L006
## JMS8-3 GSM1545540_JMS8-3.txt ML 75795034 1 L006
## JMS8-4 GSM1545541_JMS8-4.txt LP 60517657 1 L006
## JMS8-5 GSM1545542_JMS8-5.txt Basal 55086324 1 L006
## JMS9-P7c GSM1545544_JMS9-P7c.txt ML 21311068 1 L008
## JMS9-P8c GSM1545545_JMS9-P8c.txt LP 19958838 1 L008
##
## $counts
## Samples
## Tags 10_6_5_11 9_6_5_11 purep53 JMS8-2 JMS8-3 JMS8-4 JMS8-5 JMS9-P7c JMS9-P8c
## 497097 1 2 342 526 3 3 535 2 0
## 100503874 0 0 5 6 0 0 5 0 0
## 100038431 0 0 0 0 0 0 1 0 0
## 19888 0 1 0 0 17 2 0 1 0
## 20671 1 1 76 40 33 14 98 18 8
## 27174 more rows ...
##
## $genes
## ENTREZID SYMBOL TXCHROM
## 1 497097 Xkr4 chr1
## 2 100503874 Gm19938 <NA>
## 3 100038431 Gm10568 <NA>
## 4 19888 Rp1 chr1
## 5 20671 Sox17 chr1
## 27174 more rows ...数据预处理
原始数据尺度转换
由于更深的测序总会产生更多的序列片段,在差异表达及相关的分析中,我们很少直接使用序列数。在实际操作时,我们通常将原始的序列数进行归一化,来消除测序深度所导致的差异。通常被使用的方法有基于序列的CPM(counts per million)、log-CPM、FPKM(fragments per kilobase of transcript per million),和基于转录本数目的RPKM(reads per kilobase of transcript per million)。
我们在分析中通常使用CPM和log-CPM转换。虽然RPKM和FPKM可以校正基因长度区别的影响,但CPM和log-CPM只使用计数矩阵即可计算,且已足以满足我们所关注的比较的需要。假设不同条件之间剪接异构体(isoform)的表达比例没有变化,差异表达分析关注的是同一基因在不同条件之间表达水平的相对差异,而不是比较多个基因之间的差异或测定绝对表达量。换而言之,基因长度在我们进行比较的不同组之间是始终不变的,且任何观测到的差异都来自于不同组的条件的变化而不是基因长度的变化。
我们使用edgeR中的cpm函数将原始计数转换为CPM和log-CPM值。如果可以提供基因长度信息,RPKM值的计算也和CPM值的计算一样简单,只需使用edgeR中的rpkm函数。
对于一个基因,CPM值为1相当于在本实验测序深度最低的样品中(JMS9-P8c, 文库大小约2千万)有20个计数,或者在测序深度最高的样品中(JMS8-3,文库大小约7.6千万)有76个计数。
log-CPM值将被用于探索性图表中。当设置log=TRUE时,cpm函数会给CPM值加上一个弥补值并进行log2转换。默认的弥补值是2/L,其中2是“预先计数”,而L是样本文库大小(以百万计)的平均值,所以log-CPM值是根据CPM值通过log2(CPM + 2/L)计算得到的。这样的计算方式可以确保任意两个具有相同CPM值的序列片段计数的log-CPM值也相同。弥补值的使用可以避免对零取对数,并能使所有样本间的对数倍数变化(log-fold-change)向0推移而减小低表达基因间微小计数变化带来的巨大的伪差异性,这对于绘制探索性图表很有帮助。在这个数据集中,平均的样本文库大小是4.55千万,所以L约等于45.5,且每个样本中的最小log-CPM值为log2(2/45.5) = -4.51。换而言之,在加上了预先计数弥补值后,此数据集中的零表达计数对应的log-CPM值为-4.51:
## [1] 45.5 51.4
summary(lcpm)## 10_6_5_11 9_6_5_11 purep53 JMS8-2 JMS8-3
## Min. :-4.51 Min. :-4.51 Min. :-4.51 Min. :-4.51 Min. :-4.51
## 1st Qu.:-4.51 1st Qu.:-4.51 1st Qu.:-4.51 1st Qu.:-4.51 1st Qu.:-4.51
## Median :-0.68 Median :-0.36 Median :-0.10 Median :-0.09 Median :-0.43
## Mean : 0.17 Mean : 0.33 Mean : 0.44 Mean : 0.41 Mean : 0.32
## 3rd Qu.: 4.29 3rd Qu.: 4.56 3rd Qu.: 4.60 3rd Qu.: 4.55 3rd Qu.: 4.58
## Max. :14.76 Max. :13.50 Max. :12.96 Max. :12.85 Max. :12.96
## JMS8-4 JMS8-5 JMS9-P7c JMS9-P8c
## Min. :-4.51 Min. :-4.51 Min. :-4.51 Min. :-4.51
## 1st Qu.:-4.51 1st Qu.:-4.51 1st Qu.:-4.51 1st Qu.:-4.51
## Median :-0.41 Median :-0.07 Median :-0.17 Median :-0.33
## Mean : 0.25 Mean : 0.40 Mean : 0.37 Mean : 0.27
## 3rd Qu.: 4.32 3rd Qu.: 4.43 3rd Qu.: 4.60 3rd Qu.: 4.44
## Max. :14.85 Max. :13.19 Max. :12.94 Max. :14.01在接下来的线性模型分析中,使用limma的voom函数时也会用到log-CPM值,但voom会默认使用更小的预先计数重新计算自己的log-CPM值。
删除低表达基因
所有数据集中都混有表达的基因与不表达的基因。我们想要检测在一种条件中表达但在另一种条件中不表达的基因,但也有一些基因在所有样品中都不表达。实际上,这个数据集中19%的基因在所有九个样品中的计数都是零。
##
## FALSE TRUE
## 22026 5153log-CPM值的分布图表显示每个样本中很大一部分基因都是不表达或者表达程度相当低的,它们的log-CPM值非常小甚至是负的(图1A)。
在任何样本中都没有足够多的序列片段的基因应该从下游分析中过滤掉。这样做的原因有好几个。 从生物学的角度来看,在任何条件下的表达水平都不具有生物学意义的基因都不值得关注,因此最好忽略。 从统计学的角度来看,去除低表达计数基因使数据中的均值 - 方差关系可以得到更精确的估计,并且还减少了下游的差异表达分析中需要进行的统计检验的数量。
edgeR包中的filterByExpr函数提供了自动过滤基因的方法,可保留尽可能多的有足够表达计数的基因。
keep.exprs <- filterByExpr(x, group=group)
x <- x[keep.exprs,, keep.lib.sizes=FALSE]
dim(x)## [1] 16624 9此函数默认选取最小的组内的样本数量为最小样本数,保留至少在这个数量的样本中有10个或更多计数的基因。实际进行过滤时,使用的是CPM值而不是表达计数,以避免对总序列数大的样本的偏向性。在这个数据集中,总序列数的中位数是5.1千万,且10/51约等于0.2,所以filterByExpr函数保留在至少三个样本中CPM值大于等于0.2的基因。在我们的此次实验中,一个具有生物学意义的基因需要在至少三个样本中表达,因为三种细胞类型组内各有三个重复。过滤的阈值取决于测序深度和实验设计。如果样本总表达计数量增大,那么可以选择更低的CPM阈值,因为更大的总表达计数量提供了更好的分辨率来探究更多表达水平更低的基因。
使用这个标准,基因的数量减少到了16624个,约为开始时数量的60%。过滤后的log-CPM值显示出每个样本的分布基本相同(下图B部分)。需要注意的是,从整个DGEList对象中取子集时同时删除了被过滤的基因的计数和其相关的基因信息。留下的基因相对应的基因信息和计数在过滤后的DGEList对象中被保留。
下方给出的是绘图所用代码。
lcpm.cutoff <- log2(10/M + 2/L)
library(RColorBrewer)
nsamples <- ncol(x)
col <- brewer.pal(nsamples, "Paired")
par(mfrow=c(1,2))
plot(density(lcpm[,1]), col=col[1], lwd=2, ylim=c(0,0.26), las=2, main="", xlab="")
title(main="A. Raw data", xlab="Log-cpm")
abline(v=lcpm.cutoff, lty=3)
for (i in 2:nsamples){
den <- density(lcpm[,i])
lines(den$x, den$y, col=col[i], lwd=2)
}
legend("topright", samplenames, text.col=col, bty="n")
lcpm <- cpm(x, log=TRUE)
plot(density(lcpm[,1]), col=col[1], lwd=2, ylim=c(0,0.26), las=2, main="", xlab="")
title(main="B. Filtered data", xlab="Log-cpm")
abline(v=lcpm.cutoff, lty=3)
for (i in 2:nsamples){
den <- density(lcpm[,i])
lines(den$x, den$y, col=col[i], lwd=2)
}
legend("topright", samplenames, text.col=col, bty="n")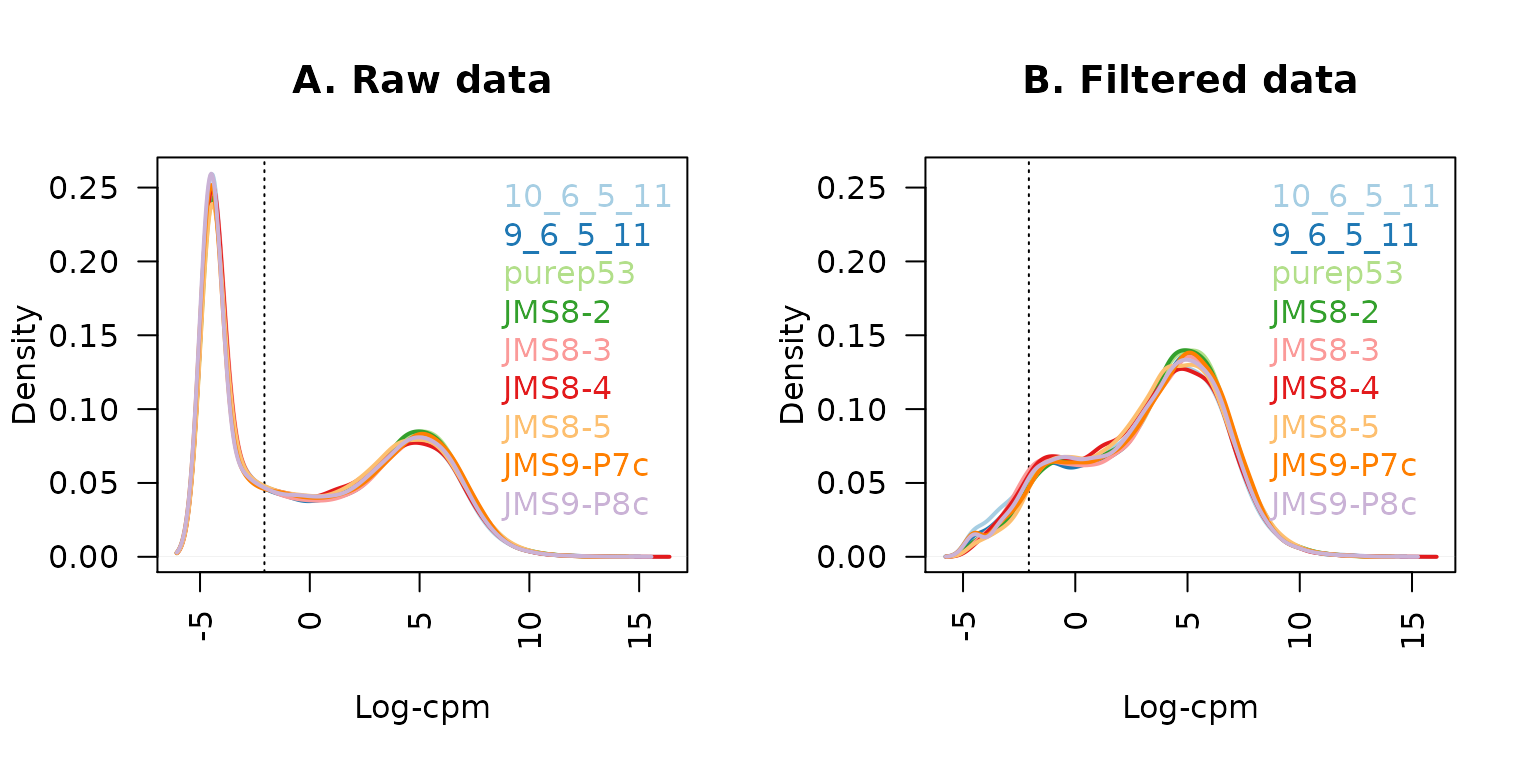
每个样本过滤前的原始数据(A)和过滤后(B)的数据的log-CPM值密度。竖直虚线标出了过滤步骤中所用阈值(相当于CPM值为约0.2)。
归一化基因表达分布
在样品制备或测序过程中,不具备生物学意义的外部因素会影响单个样品的表达。比如说,在实验中第一批制备的样品会总体上表达高于第二批制备的样品。差异表达分析假设所有样品表达值的范围和分布都应当相似。我们需要进行归一化来确保整个实验中每个样本的表达分布都相似。
密度图和箱线图等展示每个样品基因表达量分布的图表可以用于判断是否有样品和其他样品分布有差异。在此数据集中,所有样品的log-CPM分布都很相似(上图B部分)。
尽管如此,我们依然需要使用edgeR中的calcNormFactors函数,用TMM(Robinson and Oshlack 2010)方法进行归一化。此处计算得到的归一化系数被用作文库大小的缩放系数。当我们使用DGEList对象时,这些归一化系数被自动存储在x$samples$norm.factors。对此数据集而言,TMM归一化的作用比较温和,这体现在所有的缩放因子都相对接近1。
x <- calcNormFactors(x, method = "TMM")
x$samples$norm.factors## [1] 0.894 1.025 1.046 1.046 1.016 0.922 0.996 1.086 0.984在这里,为了更好地展示出归一化的效果,我们复制了数据并进行了人工调整,使得第一个样品的计数减少到了其原始值的5%,而第二个样品增大到了5倍。要注意在实际的数据分析流程中,不应当进行这样的操作。
x2 <- x
x2$samples$norm.factors <- 1
x2$counts[,1] <- ceiling(x2$counts[,1]*0.05)
x2$counts[,2] <- x2$counts[,2]*5下图显示了没有经过归一化的与经过了归一化的数据的表达分布,其中归一化前不同样本的分布明显不同,而归一化后比较相似。此处,经过我们人工调整的第一个样品的TMM缩放系数0.06非常小,而第二个样品的缩放系数6.08很大,它们都并不接近1。
par(mfrow=c(1,2))
lcpm <- cpm(x2, log=TRUE)
boxplot(lcpm, las=2, col=col, main="")
title(main="A. Example: Unnormalised data",ylab="Log-cpm")
x2 <- calcNormFactors(x2)
x2$samples$norm.factors## [1] 0.0577 6.0829 1.2202 1.1648 1.1966 1.0466 1.1505 1.2543 1.1090
lcpm <- cpm(x2, log=TRUE)
boxplot(lcpm, las=2, col=col, main="")
title(main="B. Example: Normalised data",ylab="Log-cpm")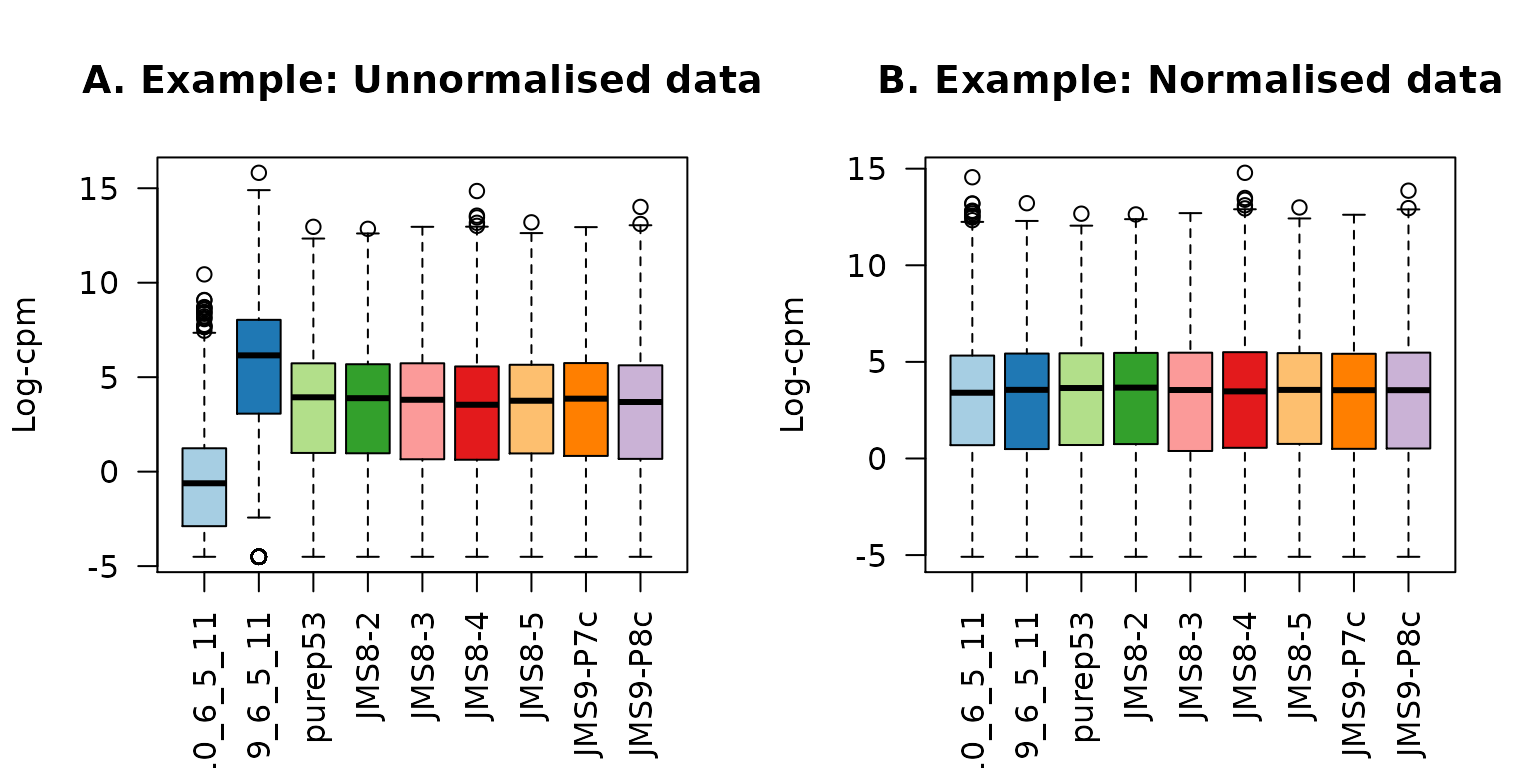
样例数据:log-CPM值的箱线图展示了未经归一化的数据(A)及归一化后的数据(B)中每个样本的表达分布。数据集经过调整,样本1和2中的表达计数分别被缩放到其原始值的5%和500%。
降维
在我们看来,用于检查基因表达分析的最重要的探索性图表之一便是MDS图,或类似的图。这种图表使用无监督聚类方法展示出了样品间的相似性和不相似性,能让我们在进行正式的检验之前对于能检测到多少差异表达基因有个大致概念。理想情况下,样本会在各个实验组内很好的聚类,且我们可以鉴别出远离所属组的样本,并追踪误差或额外方差的来源。如果存在的话,技术重复应当互相非常接近。
这样的图可以用limma中的plotMDS函数绘制。第一个维度表示能够最好地分离样品且解释最大比例的方差的领先倍数变化(leading-fold-change),而后续的维度的影响更小,并与之前的维度正交。当实验设计涉及到多个因子时,建议在多个维度上检查每个因子。如果在其中一些维度上样本可按照某因子聚类,这说明该因子对于表达差异有影响,在线性模型中应当将其包括进去。反之,没有或者仅有微小影响的因子在下游分析时应当被剔除。
在这个数据集中,可以看出样本在维度1和2能很好地按照实验分组聚类,随后在维度3按照测序泳道(样品批次)分离(如下图所示)。由于第一维度解释了数据中最大比例的方差,我们会发现当关注更高维度时,维度上的取值范围会变小。
尽管所有样本都按组聚类,在维度1上最大的转录差异出现在basal和LP以及basal和ML之间。因此,预期在basal样品与其他之间的成对比较中能够得到大量的DE基因,而在ML和LP之间的比较中得到的DE基因数量略少。在其他的数据集中,不按照实验组聚类的样本可能在下游分析中只表现出较小的或不表现出差异表达。
为绘制MDS图,我们为不同的因子设立不同的配色。维度1和2以细胞类型上色,而维度3和4以测序泳道(批次)上色。
lcpm <- cpm(x, log=TRUE)
par(mfrow=c(1,2))
col.group <- group
levels(col.group) <- brewer.pal(nlevels(col.group), "Set1")
col.group <- as.character(col.group)
col.lane <- lane
levels(col.lane) <- brewer.pal(nlevels(col.lane), "Set2")
col.lane <- as.character(col.lane)
plotMDS(lcpm, labels=group, col=col.group)
title(main="A. Sample groups")
plotMDS(lcpm, labels=lane, col=col.lane, dim=c(3,4))
title(main="B. Sequencing lanes")
以样品分组上色并标记的log-CPM值在维度1和2的MDS图(A)和以测序泳道上色并标记的维度3和4的MDS图(B)。图中的距离对应于领先倍数变化(leading fold-change),默认情况下也就是前500个在每对样品之间差异最大的基因的平均(均方根)log2倍数变化。
作为另一种绘制MDS图的方式,Glimma包提供了便于探索多个维度的交互式MDS图。其中的glMDSPlot函数可生成一个html网页(如果设置launch=TRUE参数,将会在生成后直接在浏览器中打开),其左侧面板含有一张MDS图,而右侧面板包含一张展示了各个维度所解释的方差比例的柱形图。点击柱形图中的柱可切换MDS图绘制时所使用的维度,且将鼠标悬浮于单个点上可显示相应的样本标签。也可切换配色方案,以突显不同细胞类型或测序泳道(批次)。此数据集的交互式MDS图可以从http://bioinf.wehi.edu.au/folders/limmaWorkflow/glimma-plots/MDS-Plot.html看到。
差异表达分析
创建设计矩阵和对比
在此研究中,我们想知道哪些基因在我们研究的三组细胞之间以不同水平表达。我们的分析中所用到的线性模型假设数据是正态分布的。首先,我们要创建一个包含细胞类型以及测序泳道(批次)信息的设计矩阵。
design <- model.matrix(~0+group+lane)
colnames(design) <- gsub("group", "", colnames(design))
design## Basal LP ML laneL006 laneL008
## 1 0 1 0 0 0
## 2 0 0 1 0 0
## 3 1 0 0 0 0
## 4 1 0 0 1 0
## 5 0 0 1 1 0
## 6 0 1 0 1 0
## 7 1 0 0 1 0
## 8 0 0 1 0 1
## 9 0 1 0 0 1
## attr(,"assign")
## [1] 1 1 1 2 2
## attr(,"contrasts")
## attr(,"contrasts")$group
## [1] "contr.treatment"
##
## attr(,"contrasts")$lane
## [1] "contr.treatment"对于一个给定的实验,通常有多种等价的方法都能用来创建合适的设计矩阵。 比如说,~0+group+lane去除了第一个因子group的截距,但第二个因子lane的截距被保留。 此外也可以使用~group+lane,来自group和lane的截距均被保留。 理解如何解释模型中估计的系数是创建合适的设计矩阵的关键。 我们在此分析中选取第一种模型,因为在没有group的截距的情况下能更直截了当地设定模型中的对比。用于细胞群之间成对比较的对比可以在limma中用makeContrasts函数设定。
contr.matrix <- makeContrasts(
BasalvsLP = Basal-LP,
BasalvsML = Basal - ML,
LPvsML = LP - ML,
levels = colnames(design))
contr.matrix## Contrasts
## Levels BasalvsLP BasalvsML LPvsML
## Basal 1 1 0
## LP -1 0 1
## ML 0 -1 -1
## laneL006 0 0 0
## laneL008 0 0 0limma线性模型方法的核心优势之一便是其适应任意实验复杂程度的能力。简单的实验设计,比如此流程中关于细胞类型和批次的实验设计,直到更复杂的析因设计和含有交互作用项的模型,都能够被较简单地处理。当实验或技术效应可被随机效应模型(random effect model)模拟时,可以使用limma中的duplicateCorrelation函数来估计交互作用,这需要在此函数以及lmFit的线性建模步骤均指定一个block参数。
从表达计数数据中删除异方差
对于RNA-seq计数数据而言,原始计数或log-CPM值的方差并不独立于均值(Law et al. 2014)。有些差异表达分析方法使用负二项分布模型,假设均值与方差间具有二次的关系。而在limma中,假设log-CPM值符合正态分布,因此我们在对RNA-seq的log-CPM值进行线性建模时,需要使用voom函数计算每个基因的权重从而调整均值与方差的关系,否则分析得到的结果可能是错误的。
当操作DGEList对象时,voom从x中自动提取文库大小和归一化因子,以此将原始计数转换为log-CPM值。在voom中,对于log-CPM值额外的归一化可以通过设定normalize.method参数来进行。
下图左侧展示了这个数据集log-CPM值的均值-方差关系。通常而言,方差是测序实验操作中的技术差异和来自不同细胞类群的重复样本之间的生物学差异的结合,而voom图会显示出一个在均值与方差之间递减的趋势。 生物学差异高的实验通常会有更平坦的趋势,其方差值在高表达处稳定。生物学差异低的实验更倾向于急剧下降的趋势。
不仅如此,voom图也提供了对于上游所进行的过滤水平的可视化检测。如果对于低表达基因的过滤不够充分,在图上表达低的一端,受到非常低的表达计数的影响,会出现方差的下降。如果观察到了这种情况,应当回到最初的过滤步骤并提高用于该数据集的表达阈值。
当先前绘制的MDS图中发现组内重复样本的聚集与分离程度出现明显的差异时,可以用voomWithQualityWeights函数(Liu et al. 2015)来代替voom,在计算基因权重值以外还能计算每个样本的权重值。关于使用此种方式的例子参见Liu等(2016) (Liu et al. 2016)。
## An object of class "EList"
## $genes
## ENTREZID SYMBOL TXCHROM
## 1 497097 Xkr4 chr1
## 5 20671 Sox17 chr1
## 6 27395 Mrpl15 chr1
## 7 18777 Lypla1 chr1
## 9 21399 Tcea1 chr1
## 16619 more rows ...
##
## $targets
## files group lib.size norm.factors lane
## 10_6_5_11 GSM1545535_10_6_5_11.txt LP 29387429 0.894 L004
## 9_6_5_11 GSM1545536_9_6_5_11.txt ML 36212498 1.025 L004
## purep53 GSM1545538_purep53.txt Basal 59771061 1.046 L004
## JMS8-2 GSM1545539_JMS8-2.txt Basal 53711278 1.046 L006
## JMS8-3 GSM1545540_JMS8-3.txt ML 77015912 1.016 L006
## JMS8-4 GSM1545541_JMS8-4.txt LP 55769890 0.922 L006
## JMS8-5 GSM1545542_JMS8-5.txt Basal 54863512 0.996 L006
## JMS9-P7c GSM1545544_JMS9-P7c.txt ML 23139691 1.086 L008
## JMS9-P8c GSM1545545_JMS9-P8c.txt LP 19634459 0.984 L008
##
## $E
## Samples
## Tags 10_6_5_11 9_6_5_11 purep53 JMS8-2 JMS8-3 JMS8-4 JMS8-5 JMS9-P7c JMS9-P8c
## 497097 -4.29 -3.86 2.519 3.293 -4.46 -3.99 3.287 -3.210 -5.30
## 20671 -4.29 -4.59 0.356 -0.407 -1.20 -1.94 0.844 -0.323 -1.21
## 27395 3.88 4.41 4.517 4.562 4.34 3.79 3.899 4.340 4.12
## 18777 4.71 5.57 5.396 5.162 5.65 5.08 5.060 5.751 5.14
## 21399 4.79 4.75 5.370 5.122 4.87 4.94 5.138 5.031 4.98
## 16619 more rows ...
##
## $weights
## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9]
## [1,] 1.08 1.33 19.8 20.27 1.99 1.40 20.49 1.11 1.08
## [2,] 1.17 1.46 4.8 8.66 3.61 2.63 8.76 3.21 2.54
## [3,] 20.22 25.57 30.4 28.53 31.35 25.74 28.72 21.20 16.66
## [4,] 26.95 32.51 33.6 33.23 34.23 32.35 33.33 30.35 24.26
## [5,] 26.61 28.50 33.6 33.21 33.57 32.00 33.31 25.17 23.57
## 16619 more rows ...
##
## $design
## Basal LP ML laneL006 laneL008
## 1 0 1 0 0 0
## 2 0 0 1 0 0
## 3 1 0 0 0 0
## 4 1 0 0 1 0
## 5 0 0 1 1 0
## 6 0 1 0 1 0
## 7 1 0 0 1 0
## 8 0 0 1 0 1
## 9 0 1 0 0 1
## attr(,"assign")
## [1] 1 1 1 2 2
## attr(,"contrasts")
## attr(,"contrasts")$group
## [1] "contr.treatment"
##
## attr(,"contrasts")$lane
## [1] "contr.treatment"
vfit <- lmFit(v, design)
vfit <- contrasts.fit(vfit, contrasts=contr.matrix)
efit <- eBayes(vfit)
plotSA(efit, main="Final model: Mean-variance trend")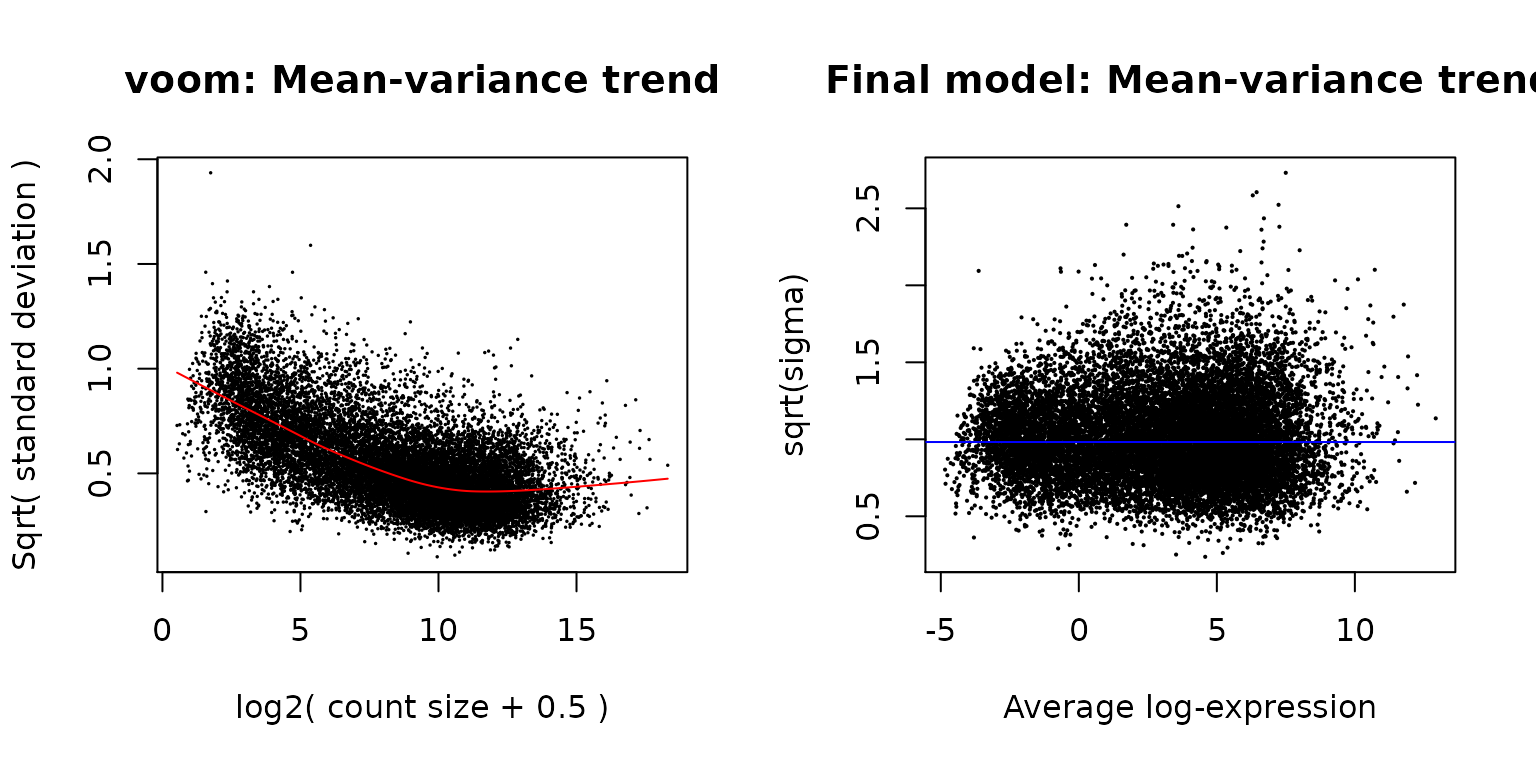
图中绘制了每个基因的均值(x轴)和方差(y轴),显示了在该数据上使用voom前它们之间的相关性(左),以及当运用voom的权重后这种趋势是如何消除的(右)。左侧的图是使用voom函数绘制的,它为log-CPM转换后的数据拟合线性模型并提取残差方差。然后,对方差取四次方根(或对标准差取平方根),并相对每个基因的平均表达作图。均值通过平均计数加上2再进行log2转换计算得到。右侧的图使用plotSA绘制了log2残差标准差与log-CPM均值的关系。在这两幅图中,每个黑点表示一个基因。左侧图中,红色曲线展示了用于计算voom权重的估算所得的均值-方差趋势。右侧图中,由经验贝叶斯算法得到的平均log2残差标准差由水平蓝线标出。
需要注意DGEList对象中的其他数据框,即基因和样本信息,也保留在了voom创建的EList对象v中。v$genes数据框等同于x$genes,v$targets等同于x$samples,而v$E中所储存的表达值类似于进行了log-CPM转换后的x$counts。此外,voom的EList对象中还有一个权重值的矩阵v$weights,而设计矩阵存储于v$design。
拟合线性模型以进行比较
limma的线性建模使用lmFit和contrasts.fit函数进行,它们原先是为微阵列而设计的。这些函数不仅可以用于微阵列数据,也可以用于使用voom计算了基因权重后的RNA-seq数据。每个基因的表达值都会单独拟合一个模型。然后通过借用全体基因的信息来进行经验贝叶斯调整(empirical Bayes moderation),这样可以更精确地估算各基因的差异性(Smyth 2004)。图4为此模型的残差关于平均表达值的图。从图中可以看出,方差不再与表达水平均值相关。
检查DE基因数量
为快速查看表达差异水平,显著上调或下调的基因可以汇总到一个表格中。显著性的判断使用默认的校正p值阈值,即5%。在basal与LP的表达水平之间的比较中,发现了4648个在basal中相较于LP下调的基因,和4863个在basal中相较于LP上调的基因,即共9511个差异表达基因。在basal和ML之间发现了一共9598个差异表达基因(4927个下调基因和4671个上调基因),而在LP和ML中发现了一共5652个差异表达基因(3135个下调基因和2517个上调基因)。在basal类群所参与的比较中皆找到了大量的差异表达基因,这与我们在MDS图中观察到的结果相吻合。
summary(decideTests(efit))## BasalvsLP BasalvsML LPvsML
## Down 4648 4927 3135
## NotSig 7113 7026 10972
## Up 4863 4671 2517在某些时候,不仅仅需要用到校正p值阈值,还需要差异倍数的对数(log-FCs)也高于某个最小值来更为严格地定义显著性。treat方法(McCarthy and Smyth 2009)可以按照对最小log-FC值的要求,使用经过经验贝叶斯调整的t统计值计算p值。当我们要求差异表达基因的log-FC显著大于1(等同于不同细胞类群之间表达量差两倍)并对此进行检验时,差异表达基因的数量得到了下降,basal与LP相比只有3684个差异表达基因,basal与ML相比只有3834个差异表达基因,LP与ML相比只有414个差异表达基因。
tfit <- treat(vfit, lfc=1)
dt <- decideTests(tfit)
summary(dt)## BasalvsLP BasalvsML LPvsML
## Down 1632 1777 224
## NotSig 12976 12790 16210
## Up 2016 2057 190在多个对比中皆差异表达的基因可以从decideTests的结果中提取,其中的0代表不差异表达的基因,1代表上调的基因,-1代表下调的基因。共有2784个基因在basal和LP以及basal和ML的比较中都差异表达,其中的20个于下方列出。write.fit函数可用于将三个比较的结果一起提取并写入一个输出文件。
## [1] 2784
head(tfit$genes$SYMBOL[de.common], n=20)## [1] "Xkr4" "Rgs20" "Cpa6" "A830018L16Rik" "Sulf1"
## [6] "Eya1" "Msc" "Sbspon" "Pi15" "Crispld1"
## [11] "Kcnq5" "Rims1" "Khdrbs2" "Ptpn18" "Prss39"
## [16] "Arhgef4" "Cnga3" "Cracdl" "Aff3" "Npas2"
vennDiagram(dt[,1:2], circle.col=c("turquoise", "salmon"))
韦恩图展示了仅basal和LP(左)、仅basal和ML(右)的对比的DE基因数量,还有两种对比中共同的DE基因数量(中)。在任何对比中均不差异表达的基因数量标于右下。
write.fit(tfit, dt, file="results.txt")从头到尾检查单个DE基因
使用topTreat函数可以列举出使用treat得到的结果中靠前的DE基因(对于eBayes的结果则应使用topTable函数)。默认情况下,topTreat将基因按照经过多重假设检验校正的p值从小到大排列,并为每个基因给出相关的基因信息、log-FC、平均log-CPM、校正t值、原始及校正p值。列出前多少个基因的数量可由用户设定,如果设为n=Inf则会包括所有的基因。基因Cldn7和Rasef在basal与LP和basal于ML的比较中都位于DE基因的前几名。
basal.vs.lp <- topTreat(tfit, coef=1, n=Inf)
basal.vs.ml <- topTreat(tfit, coef=2, n=Inf)
head(basal.vs.lp)## ENTREZID SYMBOL TXCHROM logFC AveExpr t P.Value adj.P.Val
## 12759 12759 Clu chr14 -5.46 8.86 -33.6 1.72e-10 1.71e-06
## 53624 53624 Cldn7 chr11 -5.53 6.30 -32.0 2.58e-10 1.71e-06
## 242505 242505 Rasef chr4 -5.94 5.12 -31.3 3.08e-10 1.71e-06
## 67451 67451 Pkp2 chr16 -5.74 4.42 -29.9 4.58e-10 1.74e-06
## 228543 228543 Rhov chr2 -6.26 5.49 -29.1 5.78e-10 1.74e-06
## 70350 70350 Basp1 chr15 -6.08 5.25 -28.3 7.27e-10 1.74e-06
head(basal.vs.ml)## ENTREZID SYMBOL TXCHROM logFC AveExpr t P.Value adj.P.Val
## 242505 242505 Rasef chr4 -6.53 5.12 -35.1 1.23e-10 1.24e-06
## 53624 53624 Cldn7 chr11 -5.50 6.30 -31.7 2.77e-10 1.24e-06
## 12521 12521 Cd82 chr2 -4.69 7.07 -31.4 2.91e-10 1.24e-06
## 20661 20661 Sort1 chr3 -4.93 6.70 -30.7 3.56e-10 1.24e-06
## 71740 71740 Nectin4 chr1 -5.58 5.16 -30.6 3.72e-10 1.24e-06
## 12759 12759 Clu chr14 -4.69 8.86 -28.0 7.69e-10 1.48e-06实用的差异表达结果可视化
为可视化地总结所有基因的结果,可使用plotMD函数绘制均值-差异关系(MD)图,其中展示了线性模型拟合所得到的每个基因log-FC与log-CPM平均值间的关系,而差异表达的基因会被重点标出。
Glimma的glMDPlot函数提供了交互式的均值-差异图,拓展了这种图表的功能。此函数的输出为一个html页面,左侧面板为结果的总结性图表(与plotMD的输出类似),右侧面板展示了各个样本的log-CPM值,而下方面板为结果的汇总表。这使得用户可以使用提供的注释中的信息(比如基因符号)搜索特定基因,而这在R统计图中是做不到的。
glMDPlot(tfit, coef=1, status=dt, main=colnames(tfit)[1],
side.main="ENTREZID", counts=lcpm, groups=group, launch=FALSE)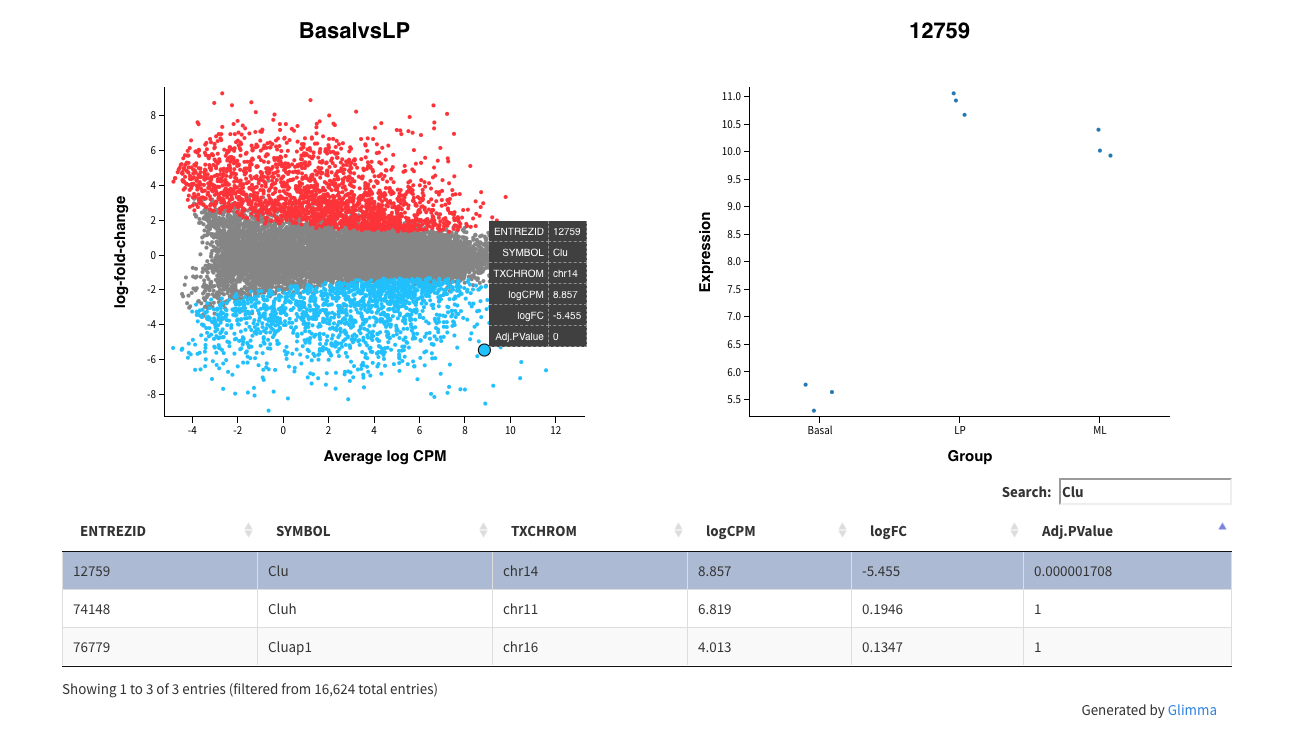
使用Glimma生成的均值-差异图。左侧面板显示了总结性数据(log-FC与log-CPM值的关系),其中选中的基因在每个样本中的数值显示于右侧面板。下方为结果的表格,其搜索框使用户得以使用可行的注释信息查找某个特定基因,如基因符号Clu。
上方指令生成的均值-差异图可以在线访问(详见http://bioinf.wehi.edu.au/folders/limmaWorkflow/glimma-plots/MD-Plot.html)。Glimma提供的交互性使得单个图形窗口内能够呈现出额外的信息。 Glimma是以R和Javascript实现的,使用R代码生成数据,并在之后使用Javascript库D3(https://d3js.org)转换为图形,使用Bootstrap库处理界面并生成互动性可搜索的表格的数据表。这使得图表可以在任意当代浏览器中直接查看而无需后段服务器时刻运行,对于将其作为关联文件附加在Rmarkdown分析报告中而言非常方便。
前文所展示的图表中,一些仅展示了在任意一个条件下表达的所有基因而缺少单个基因的具体信息(比如不同对比中共同差异表达基因的韦恩图或均值-差异图),而另一些仅展示单个基因(交互式均值-差异图右边面板中所展示的log-CPM值)。而热图使用户得以查看某一小组基因的表达情况,既便于查看单个组或样本的表达,又不至于在关注于单个基因时失去对于整体的注意,也不会造成由于对上千个基因取平均值而导致的分辨率丢失。
使用gplots包的heatmap.2函数,我们为basal与LP的对照中前100个差异表达基因(按校正p值排序)绘制了一幅热图。此热图中正确地将样本按照细胞类型聚类,并重新排序了基因,表达相似的基因形成了块状。从热图中,我们发现basal与LP之间的前100个差异表达基因在ML和LP样本中的表达非常相似。
library(gplots)
basal.vs.lp.topgenes <- basal.vs.lp$ENTREZID[1:100]
i <- which(v$genes$ENTREZID %in% basal.vs.lp.topgenes)
mycol <- colorpanel(1000,"blue","white","red")
heatmap.2(lcpm[i,], scale="row",
labRow=v$genes$SYMBOL[i], labCol=group,
col=mycol, trace="none", density.info="none",
margin=c(8,6), lhei=c(2,10), dendrogram="column")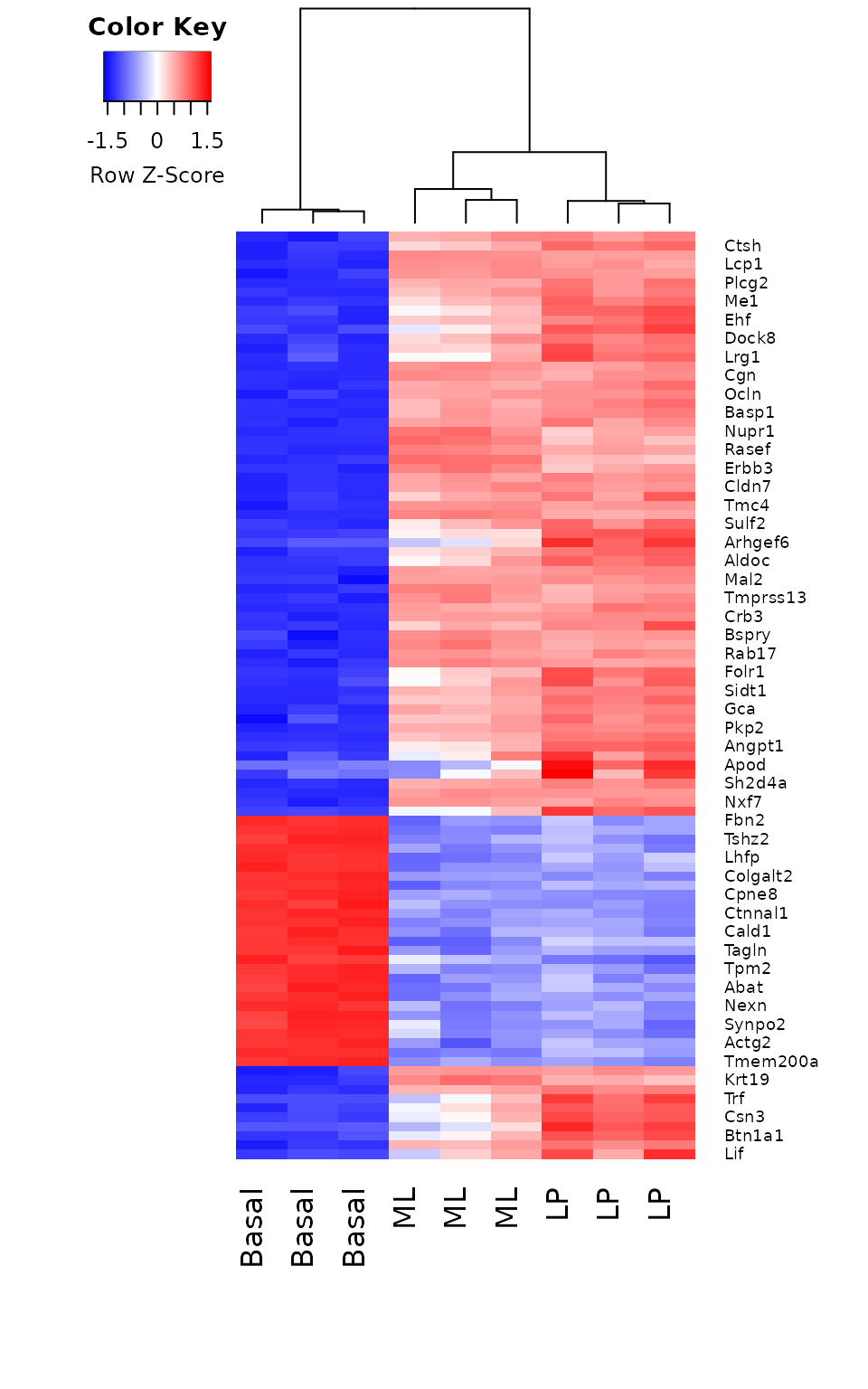
在basal和LP的对比中前100个DE基因log-CPM值的热图。经过缩放调整后,每个基因(每行)的表达均值为0,并且标准差为1。给定基因相对高表达的样本被标记为红色,相对低表达的样本被标记为蓝色。浅色和白色代表中等表达水平的基因。样本和基因已通过分层聚类的方法重新排序。图中显示有样本聚类的树状图。
使用camera的基因集检验
在此次分析的最后,我们要进行一些基因集检验。为此,我们将camera方法(Wu and Smyth 2012)应用于Broad Institute的MSigDB c2中的(Subramanian et al. 2005)中适应小鼠的c2基因表达特征,这可从http://bioinf.wehi.edu.au/software/MSigDB/以RData对象格式获取。 此外,对于人类和小鼠,来自MSigDB的其他有用的基因集也可从此网站获取,比如标志(hallmark)基因集。C2基因集的内容收集自在线数据库、出版物以及该领域专家,而标志基因集的内容来自MSigDB,从而获得具有明确定义的生物状态或过程。
load(system.file("extdata", "mouse_c2_v5p1.rda", package = "RNAseq123"))
idx <- ids2indices(Mm.c2,id=rownames(v))
cam.BasalvsLP <- camera(v,idx,design,contrast=contr.matrix[,1])
head(cam.BasalvsLP,5)## NGenes Direction PValue FDR
## LIM_MAMMARY_STEM_CELL_UP 791 Up 1.77e-18 8.36e-15
## LIM_MAMMARY_STEM_CELL_DN 683 Down 4.03e-14 8.69e-11
## ROSTY_CERVICAL_CANCER_PROLIFERATION_CLUSTER 170 Up 5.52e-14 8.69e-11
## LIM_MAMMARY_LUMINAL_PROGENITOR_UP 94 Down 2.74e-13 3.23e-10
## SOTIRIOU_BREAST_CANCER_GRADE_1_VS_3_UP 190 Up 5.16e-13 4.87e-10## NGenes Direction PValue FDR
## LIM_MAMMARY_STEM_CELL_UP 791 Up 1.68e-22 7.92e-19
## LIM_MAMMARY_STEM_CELL_DN 683 Down 7.79e-18 1.84e-14
## LIM_MAMMARY_LUMINAL_MATURE_DN 172 Up 9.74e-16 1.53e-12
## LIM_MAMMARY_LUMINAL_MATURE_UP 204 Down 1.15e-12 1.36e-09
## NAKAYAMA_SOFT_TISSUE_TUMORS_PCA2_UP 137 Up 2.24e-12 1.88e-09## NGenes Direction PValue FDR
## LIM_MAMMARY_LUMINAL_MATURE_DN 172 Up 6.73e-14 2.35e-10
## LIM_MAMMARY_LUMINAL_MATURE_UP 204 Down 9.97e-14 2.35e-10
## LIM_MAMMARY_LUMINAL_PROGENITOR_UP 94 Up 1.32e-11 2.08e-08
## REACTOME_RESPIRATORY_ELECTRON_TRANSPORT 94 Down 7.01e-09 8.28e-06
## REACTOME_RNA_POL_I_PROMOTER_OPENING 46 Down 2.04e-08 1.93e-05camera函数通过比较假设检验来评估一个给定基因集中的基因是否相对于不在集内的基因而言在差异表达基因的排序中更靠前。 它使用limma的线性模型框架,并同时采用设计矩阵和对比矩阵(如果有的话),且在检验的过程中会运用到来自voom的权重值。 在通过基因间相关性(默认设定为0.01,但也可通过数据估计)和基因集的规模得到方差膨胀因子(variance inflation factor),并使用它调整基因集检验统计值的方差后,将会返回根据多重假设检验进行了校正的p值。
Lim等人(2010)(Lim et al. 2010)使用Illumina微阵列分析了与此实验相同的分选细胞群,而我们的实验是与他们的数据集等价的RNA-seq,因此我们预期来自该早期文献的基因表达特征将会出现在每种对比的列表顶端,而结果正符合我们的预期。在LP和ML的对比中,我们为Lim等人(2010)的成熟管腔基因集(上调及下调)绘制了条码图(barcodeplot)。由于我们的对比是将LP与ML相比而不是相反,这些基因集的方向在我们的数据集中是反过来的(如果将对比反过来,基因集的方向将会与对比一致)。
barcodeplot(efit$t[,3], index=idx$LIM_MAMMARY_LUMINAL_MATURE_UP,
index2=idx$LIM_MAMMARY_LUMINAL_MATURE_DN, main="LPvsML")![`LIM_MAMMARY_LUMINAL_MATURE_UP` (红色条形,图表上方)和`LIM_MAMMARY_LUMINAL_MATURE_DN`(蓝色条形,图表下方)基因集在LP和ML的对比中的条码图,每个基因集都有一条富集线展示了竖直条形在图表每部分的相对富集程度。Lim等人的实验[@Lim:BreastCancerRes:2010]与我们的非常相似,用了相同的方式分选获取细胞群,只是他们使用了微阵列而不是RNA-seq来测定基因表达。需要注意上调基因集发生下调而下调基因集发生上调的逆相关性来自于对比的设定方式(LP相比于ML),如果将其对调,方向性将会吻合。](limmaWorkflow_chinese_files/figure-html/barcodeplot-1.png)
LIM_MAMMARY_LUMINAL_MATURE_UP (红色条形,图表上方)和LIM_MAMMARY_LUMINAL_MATURE_DN(蓝色条形,图表下方)基因集在LP和ML的对比中的条码图,每个基因集都有一条富集线展示了竖直条形在图表每部分的相对富集程度。Lim等人的实验(Lim et al. 2010)与我们的非常相似,用了相同的方式分选获取细胞群,只是他们使用了微阵列而不是RNA-seq来测定基因表达。需要注意上调基因集发生下调而下调基因集发生上调的逆相关性来自于对比的设定方式(LP相比于ML),如果将其对调,方向性将会吻合。
limma还提供了另外的基因集检验方法,比如mroast(Wu et al. 2010)的自包含检验。camera适用于检验包含许多基因集的大型数据库中哪些基因集相对于其他基因集整体变化更为显著(如前文所示),自包含检验则更善于集中检验一个或少个选中的基因集自身是否差异表达。换句话说,camera更适用于找出具有意义的基因集,而mroast测试的是已经确定有意义的基因集的显著性。
使用到的软件和代码
此RNA-seq工作流程使用了Bioconductor项目3.8版本中的多个软件包,运行于R 3.5.1或更高版本。除了本文中着重介绍的软件(limma、Glimma以及edgeR),还用到了一些其他软件包,包括gplots和RColorBrewer还有基因注释包Mus.musculus。 此文档使用knitr编译。所有用到的包的版本号如下所示。 Bioconductor工作流程包RNAseq123(可访问https://bioconductor.org/packages/RNAseq123查看)内包含此文章的英文和简体中文版以及进行此分析流程所需要的全部代码。安装此包即可安装以上提到的所有需要的包。对于RNA-seq数据分析实践培训而言,此包也是非常有用的资源。
## R version 4.0.3 (2020-10-10)
## Platform: x86_64-pc-linux-gnu (64-bit)
## Running under: Ubuntu 20.04 LTS
##
## Matrix products: default
## BLAS/LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.8.so
##
## locale:
## [1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C LC_TIME=en_US.UTF-8
## [4] LC_COLLATE=en_US.UTF-8 LC_MONETARY=en_US.UTF-8 LC_MESSAGES=C
## [7] LC_PAPER=en_US.UTF-8 LC_NAME=C LC_ADDRESS=C
## [10] LC_TELEPHONE=C LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
##
## attached base packages:
## [1] parallel stats4 stats graphics grDevices utils datasets methods
## [9] base
##
## other attached packages:
## [1] gplots_3.1.1 RColorBrewer_1.1-2
## [3] Mus.musculus_1.3.1 TxDb.Mmusculus.UCSC.mm10.knownGene_3.10.0
## [5] org.Mm.eg.db_3.12.0 GO.db_3.12.1
## [7] OrganismDbi_1.32.0 GenomicFeatures_1.42.1
## [9] GenomicRanges_1.42.0 GenomeInfoDb_1.26.2
## [11] AnnotationDbi_1.52.0 IRanges_2.24.0
## [13] S4Vectors_0.28.0 Biobase_2.50.0
## [15] BiocGenerics_0.36.0 edgeR_3.32.0
## [17] Glimma_2.0.0 limma_3.46.0
## [19] knitr_1.30 BiocStyle_2.18.1
##
## loaded via a namespace (and not attached):
## [1] colorspace_2.0-0 ellipsis_0.3.1 rprojroot_2.0.2
## [4] XVector_0.30.0 fs_1.5.0 bit64_4.0.5
## [7] xml2_1.3.2 splines_4.0.3 R.methodsS3_1.8.1
## [10] geneplotter_1.68.0 jsonlite_1.7.2 Rsamtools_2.6.0
## [13] annotate_1.68.0 dbplyr_2.0.0 R.oo_1.24.0
## [16] graph_1.68.0 BiocManager_1.30.10 compiler_4.0.3
## [19] httr_1.4.2 assertthat_0.2.1 Matrix_1.2-18
## [22] htmltools_0.5.0 prettyunits_1.1.1 tools_4.0.3
## [25] gtable_0.3.0 glue_1.4.2 GenomeInfoDbData_1.2.4
## [28] dplyr_1.0.2 rappdirs_0.3.1 Rcpp_1.0.5
## [31] pkgdown_1.6.1 vctrs_0.3.5 Biostrings_2.58.0
## [34] rtracklayer_1.50.0 xfun_0.19 stringr_1.4.0
## [37] lifecycle_0.2.0 gtools_3.8.2 XML_3.99-0.5
## [40] zlibbioc_1.36.0 scales_1.1.1 ragg_0.4.0
## [43] hms_0.5.3 MatrixGenerics_1.2.0 SummarizedExperiment_1.20.0
## [46] RBGL_1.66.0 yaml_2.2.1 curl_4.3
## [49] memoise_1.1.0 ggplot2_3.3.2 biomaRt_2.46.0
## [52] stringi_1.5.3 RSQLite_2.2.1 highr_0.8
## [55] genefilter_1.72.0 desc_1.2.0 caTools_1.18.0
## [58] BiocParallel_1.24.1 rlang_0.4.9 pkgconfig_2.0.3
## [61] systemfonts_0.3.2 matrixStats_0.57.0 bitops_1.0-6
## [64] evaluate_0.14 lattice_0.20-41 purrr_0.3.4
## [67] GenomicAlignments_1.26.0 htmlwidgets_1.5.2 bit_4.0.4
## [70] tidyselect_1.1.0 magrittr_2.0.1 bookdown_0.21
## [73] DESeq2_1.30.0 R6_2.5.0 generics_0.1.0
## [76] DelayedArray_0.16.0 DBI_1.1.0 pillar_1.4.7
## [79] survival_3.2-7 RCurl_1.98-1.2 tibble_3.0.4
## [82] crayon_1.3.4 KernSmooth_2.23-18 BiocFileCache_1.14.0
## [85] rmarkdown_2.5 progress_1.2.2 locfit_1.5-9.4
## [88] grid_4.0.3 blob_1.2.1 digest_0.6.27
## [91] xtable_1.8-4 R.utils_2.10.1 textshaping_0.2.1
## [94] openssl_1.4.3 munsell_0.5.0 askpass_1.1参考文献
Bioconductor Core Team. 2016a. Homo.sapiens: Annotation package for the Homo.sapiens object. https://bioconductor.org/packages/release/data/annotation/html/Homo.sapiens.html.
———. 2016b. Mus.musculus: Annotation package for the Mus.musculus object. https://bioconductor.org/packages/release/data/annotation/html/Mus.musculus.html.
Durinck, S., Y. Moreau, A. Kasprzyk, S. Davis, B. De Moor, A. Brazma, and W. Huber. 2005. “BioMart and Bioconductor: a powerful link between biological databases and microarray data analysis.” Bioinformatics 21: 3439–40.
Durinck, S., P. Spellman, E. Birney, and W. Huber. 2009. “Mapping identifiers for the integration of genomic datasets with the R/Bioconductor package biomaRt.” Nature Protocols 4: 1184–91.
Huber, W., V. J. Carey, R. Gentleman, S. Anders, M. Carlson, B. S. Carvalho, H. C. Bravo, et al. 2015. “Orchestrating High-Throughput Genomic Analysis with Bioconductor.” Nature Methods 12 (2): 115–21. http://www.nature.com/nmeth/journal/v12/n2/full/nmeth.3252.html.
Law, C. W., Y. Chen, W. Shi, and G. K. Smyth. 2014. “Voom: Precision Weights Unlock Linear Model Analysis Tools for RNA-seq Read Counts.” Genome Biology 15: R29.
Liao, Y., G. K. Smyth, and W. Shi. 2013. “The Subread Aligner: Fast, Accurate and Scalable Read Mapping by Seed-and-Vote.” Nucleic Acids Res 41 (10): e108.
———. 2014. “featureCounts: an Efficient General-Purpose Program for Assigning Sequence Reads to Genomic Features.” Bioinformatics 30 (7): 923–30.
Lim, E., D. Wu, B. Pal, T. Bouras, M. L. Asselin-Labat, F. Vaillant, H. Yagita, G. J. Lindeman, G. K. Smyth, and J. E. Visvader. 2010. “Transcriptome analyses of mouse and human mammary cell subpopulations reveal multiple conserved genes and pathways.” Breast Cancer Research 12 (2): R21.
Liu, R., K. Chen, N. Jansz, M. E. Blewitt, and M. E. Ritchie. 2016. “Transcriptional Profiling of the Epigenetic Regulator Smchd1.” Genomics Data 7: 144–7.
Liu, R., A. Z. Holik, S. Su, N. Jansz, K. Chen, H. S. Leong, M. E. Blewitt, M. L. Asselin-Labat, G. K. Smyth, and M. E. Ritchie. 2015. “Why weight? Combining voom with estimates of sample quality improves power in RNA-seq analyses.” Nucleic Acids Res 43: e97.
McCarthy, D. J., and G. K. Smyth. 2009. “Testing significance relative to a fold-change threshold is a TREAT.” Bioinformatics 25: 765–71.
Ritchie, M. E., B. Phipson, D. Wu, Y. Hu, C. W. Law, W. Shi, and G. K. Smyth. 2015. “limma Powers Differential Expression Analyses for RNA-Sequencing and Microarray Studies.” Nucleic Acids Res 43 (7): e47.
Robinson, M. D., D. J. McCarthy, and G. K. Smyth. 2010. “edgeR: A Bioconductor Package for Differential Expression Analysis of Digital Gene Expression Data.” Bioinformatics 26: 139–40.
Robinson, M. D., and A. Oshlack. 2010. “A Scaling Normalization Method for Differential Expression Analysis of RNA-seq data.” Genome Biology 11: R25.
Sheridan, J. M., M. E. Ritchie, S. A. Best, K. Jiang, T. J. Beck, F. Vaillant, K. Liu, et al. 2015. “A pooled shRNA screen for regulators of primary mammary stem and progenitor cells identifies roles for Asap1 and Prox1.” BMC Cancer 15 (1): 221.
Smyth, G. K. 2004. “Linear Models and Empirical Bayes Methods for Assessing Differential Expression in Microarray Experiments.” Stat Appl Genet Mol Biol 3 (1): Article 3.
Su, S., C. W. Law, C. Ah-Cann, M. L. Asselin-Labat, M. E. Blewitt, and M. E. Ritchie. 2017. “Glimma: Interactive Graphics for Gene Expression Analysis.” Bioinformatics 33: 2050–52.
Subramanian, A., P. Tamayo, V. K. Mootha, S. Mukherjee, B. L. Ebert, M. A. Gillette, A. Paulovich, et al. 2005. “Gene Set Enrichment Analysis: A Knowledge-Based Approach for Interpreting Genome-Wide Expression Profiles.” Proc Natl Acad Sci U S A 102 (43): 15545–50.
Wu, D., E. Lim, F. Vaillant, M. L. Asselin-Labat, J. E. Visvader, and G. K. Smyth. 2010. “ROAST: rotation gene set tests for complex microarray experiments.” Bioinformatics 26 (17): 2176–82.
Wu, D., and G. K. Smyth. 2012. “Camera: a competitive gene set test accounting for inter-gene correlation.” Nucleic Acids Res 40 (17): e133.